
01 Jan 2024
UPDATE: NOT WORKING at the moment since updating to macOS Sonoma over the holidays 🙄
Location of voice memos recordings has changed.
It seems you can find a temporary file at
/Users/my_username/Library/Containers/com.apple.VoiceMemos/Data/tmp/.com.apple.uikit.itemprovider.temporary.S0SvM0/Recording 270.m4a
and full version here:
/Users/my_username/Library/Group Containers/group.com.apple.VoiceMemos.shared/Recordings
However both locations can't be accessed by Python because of permissions 🤔
Tried:
chmod -R 755 /Users/my_username/Library/Group Containers/group.com.apple.VoiceMemos.shared/Recordings`
to no avail.
See Reddit thread:
https://www.reddit.com/r/MacOS/comments/16v0j7y/where_do_i_find_my_voice_memos_in_finder_now/
01 Oct 2024
Did some further poking around -seems the folder used by macOS now to store Voice Memos is:
~/Library/Containers/com.apple.VoiceMemos
but it's protected at system level and can't be accessed by Python.
This test script doesn't print anything -whereby it does when crawling ~/Downloads for example:
import os
import mimetypes
def is_audio_file(file_path):
mime_type, _ = mimetypes.guess_type(file_path)
return mime_type and mime_type.startswith('audio')
def find_audio_files(folder_path):
# Expand the tilde to the full home directory path
folder_path = os.path.expanduser(folder_path)
# os.walk will go through all files and directories, including hidden ones
for root, dirs, files in os.walk(folder_path, topdown=True):
try:
# print(f"Searching in: {root}")
for file in files:
file_path = os.path.join(root, file)
print(f"Checking file: {file_path}")
if is_audio_file(file_path):
print(f"Audio file found: {file_path}")
except PermissionError as e:
print(f"Permission denied for {root}. Error: {e}")
folder_path = "~/Library/Containers/com.apple.VoiceMemos"
find_audio_files(folder_path)
TODO: try giving full disk access to Python/Terminal in System Preferences > Security & Privacy > Privacy > Full Disk Access, or find other way to export programmatically from Voice Memos.
Original note
17 Sep 2022
I've been using Just Press Record Just Press Record for the last 2+ years for on-the-go, in-my-bath or at-my-desk long voice recordings.
A lot of these recordings are intended to be actioned, or serve as basis for an email, a blog or a note.
I love the simplicity and efficiency of Just Press Record, so it still requires me some tedious tasks when back at my computer to extract the transcript for each recording individually.
Ultimate goal
workflow as simple as one tap recording from phone or watch and transcript is in my notes draft folder when I get back at my desk.
Some of the script logic can also be used for transcribing meeting recordings.
First approach (discarded - see next section for final approach)
Python script to:
- fetch
.m4arecording from local iCloud folder (!helpers/icloud-drive) with one subfolder by day) - convert
.m4ato.wavwhich seems to be the primary format accepted by speech_recognition - transcribe (speech to text)
- generate markdown note in a Drafts folder in my notes folder
from pydub import AudioSegment
audio = AudioSegment.from_file('file.m4a')
import speech_recognition as sr
r = sr.Recognizer()
with sr.AudioFile('sampleMp3.WAV') as source:
audio = r.record(source, duration=60)
command = r.recognize_google(audio)
text_file = open("Output.txt", "w")
text_file.write(command)
text_file.close()
Long Sample Audio
import os
from pydub import AudioSegment
import speech_recognition as sr
from pydub.silence import split_on_silence
recognizer = sr.Recognizer()
def load_chunks(filename):
long_audio = AudioSegment.from_mp3(filename)
audio_chunks = split_on_silence(
long_audio, min_silence_len=1800,
silence_thresh=-17
)
return audio_chunks
for audio_chunk in load_chunks('./sample_audio/long_audio.mp3'):
audio_chunk.export("temp", format="wav")
with sr.AudioFile("temp") as source:
audio = recognizer.listen(source)
try:
text = recognizer.recognize_google(audio)
print("Chunk : {}".format(text))
except Exception as ex:
print("Error occured")
print(ex)
print("++++++")
from: https://hackernoon/how-to-convert-speech-to-text-in-python-q0263tzp
Getting pydub.exceptions.CouldntDecodeError: Decoding failed. ffmpeg returned error code: 1.
Need to use AudioSegment.from_file(filename, "m4a")?
# importing libraries
import speech_recognition as sr
import os
from pydub import AudioSegment
from pydub.silence import split_on_silence
# create a speech recognition object
r = sr.Recognizer()
# a function that splits the audio file into chunks
# and applies speech recognition
def get_large_audio_transcription(path):
"""
Splitting the large audio file into chunks
and apply speech recognition on each of these chunks
"""
# open the audio file using pydub
sound = AudioSegment.from_wav(path)
# split audio sound where silence is 700 miliseconds or more and get chunks
chunks = split_on_silence(sound,
# experiment with this value for your target audio file
min_silence_len = 500,
# adjust this per requirement
silence_thresh = sound.dBFS-14,
# keep the silence for 1 second, adjustable as well
keep_silence=500,
)
folder_name = "audio-chunks"
# create a directory to store the audio chunks
if not os.path.isdir(folder_name):
os.mkdir(folder_name)
whole_text = ""
# process each chunk
for i, audio_chunk in enumerate(chunks, start=1):
# export audio chunk and save it in
# the `folder_name` directory.
chunk_filename = os.path.join(folder_name, f"chunk{i}.wav")
audio_chunk.export(chunk_filename, format="wav")
# recognize the chunk
with sr.AudioFile(chunk_filename) as source:
audio_listened = r.record(source)
# try converting it to text
try:
text = r.recognize_google(audio_listened)
except sr.UnknownValueError as e:
print("Error:", str(e))
else:
text = f"{text.capitalize()}. "
print(chunk_filename, ":", text)
whole_text += text
# return the text for all chunks detected
return whole_text
from : https://www.thepythoncode.com/article/using-speech-recognition-to-convert-speech-to-text-python
Python script to convert m4a files to wav files
18 Sep 2022 Let's try to focus first on conversion to .wav and then tackle speech-recognition.
Resources


- requires an AssemblyAI account.

- The files need to be stored on Azure Blob Storage first
- need to build a websocket for it as it the other alternative within bing for large audio files

- SpeechRecognition library allows you to perform speech recognition with support for several engines and APIs, online and offline.
Final approach (Whisper)
23 Sep 2022 exploring OpenAI's new speech recognition AI "Whisper" for this project.
Worked in minutes! Using this.
Python script to:
- fetch
.m4arecordings from local iCloud folder (!helpers/icloud-drive) with one subfolder by day) - identify audio recordings not yet processed
- transcribe those with Whisper
- log raw transcript
- generate markdown note in a Drafts folder in my notes folder
Could be run manually + daily cron job.
Need to:
- create a
replacements.txtfile to list all replacements in one easy place to update - logic to handle replacements based on it
- logic to identify files already processed
Transcribe
import whisper
model = whisper.load_model("base")
result = model.transcribe('test/1.m4a')
print(f'\n{result["text"]}\n')
Clean Transcript
v = False # verbose
def clean_transcript(transcript):
### Create dict of replacements
if v:
print(f"\nCreating dict of replacements:\n")
replacements_file = 'replacements.txt'
replacements = {}
with open(replacements_file, 'r') as df:
lines = df.readlines()
for line in lines:
if not line.startswith('#'): # remove comments
# print("line: ", repr(line))
line_parts = line.split('|')
if v:
print(f"line {get_linenumber()}: {line_parts=}")
replacements[line_parts[0]] = line_parts[1][:-1] # remove trailing \n
### Remove punctuation
if ',' in transcript:
transcript = transcript.replace(',', '')
if '.' in transcript:
transcript = transcript.replace('.', '')
if v:
print(f"\nProcessing list of replacements:\n")
for k,value in replacements.items():
if v:
print(f"line {get_linenumber()}: replacing {repr(k)} with {repr(v)}")
if k in transcript:
if value == '\\n':
transcript = transcript.replace(k, '\n')
else:
transcript = transcript.replace(k, value)
if v:
print(f"\nProcessing by line:\n")
parts = transcript.split('\n')
output = []
for part in parts:
if v:
print(f"line {get_linenumber()}: {part=}")
part = my_utils.clean_beginning_string(part, v=False)
part = f"{part} " # add 2 trailing spaces for Markdown linebreaks
output.append(part)
final_output = "\n".join(output)
return final_output
with replacements.txt as:
Nick, note|Nic Note
Nicknote|Nic Note
Nick note|Nic Note
You line|\n
new line|\n
you line|\n
Dash|-
dash|-
full stop|.
Full stop|.
four step|.
full step|.
Full-step|.
full-step|.
come up|,
Call in|:
commons|comments
c | see
We were|Reword
Salves|Sales
Node|Note
.|.
,|,
?|?
question mark|?
# always leave an empty line at the end
Fetch Recordings
import os, os.path
count_recordings = 0
for root, dirs, files in os.walk("/Users/xxxx/Library/Mobile Documents/iCloud~com~openplanetsoftware~just-press-record/Documents"):
for x in os.listdir(root):
if x.endswith(".icloud"):
print(f"{x=}")
if os.path.isfile(x):
count_recordings += 1
gets .m4a.icloud files, not considered as files by Python 🤔
x='.01-27-21.m4a.icloud'
x='.20-58-36.m4a.icloud'
x='.13-51-05.m4a.icloud'
-------------------------------
main.py
count_recordings=0
seem to be hidden files as starting with .

Stuck at .icloud issue.
Look for alternative recording method?
Trying with Apple's native Voice Memos.
Files are located at ~/Library/Application Support/com.apple.voicememos/Recordings.
New flow to test:
- use Voice Memos for inputs (Watch, iPhone or Mac)
- use Hazel to trigger script upon new .m4a added to folder above
- script transcribes to Markdown note, logs the file as processed, and keeps both raw and cleaned transcripts for troubleshooting/archive
25 Sep 2022
Working script:
#### PARAMETERS TO ENTER
run = 'Apple' # Apple or JustPressRecord
count_to_do = 20
v = True # verbose flag
####
import whisper
import re
import shutil
from collections import namedtuple # to return transcript result as namedtuple
# import os, os.path
line_count_to_do = get_linenumber() - 6 # for referencing count_to_do line number in warning messages
count_processed = 0
count_already_transcribed = 0
def separator(count=50, lines=3, symbol='='):
separator = f"{symbol * count}" + '\n'
separator = f"\n{separator * lines}"
print(separator)
def transcribe(file_path, uid):
global v
model = whisper.load_model("base")
response = model.transcribe(file_path)
text = response["text"]
language = response["language"]
transcript = namedtuple('Transcript', ['text', 'language'])
final = transcript(text=text, language=language)
# Archive raw
with open(f"/Users/{USER}/Python/transcribee/raw/{uid}.txt", 'w') as file:
file.write(f"{final.language}\n{final.text}")
if v:
print(f'\n#{get_linenumber()} transcript["text"] = {transcript.text}\n')
return final # namedtuple `transcript``: (transcript.text, transcript.language)
def capitalise_sentence(og_string, v=False):
if v:
print(f"\n---start verbose capitalise_sentence (deactivate with v=False)")
print(f"\n{og_string=}")
# lowercase everything
lower_s = og_string.lower()
if v:
print(f"\n{lower_s=}")
# start of string & acronyms
final = re.sub(r"(\A\w)|"+ # start of string
"(?<!\.\w)([\.?!] )\w|"+ # after a ?/!/. and a space,
# but not after an acronym
"\w(?:\.\w)|"+ # start/middle of acronym
"(?<=\w\.)\w", # end of acronym
lambda x: x.group().upper(),
lower_s)
if v:
print(f"\nstart_string {final=}")
# I exception
if ' i ' in final:
final = final.replace(' i ', ' I ')
if v:
print(f"\n' i ' {final=}")
if " i'm " in final:
final = final.replace(" i'm ", " I'm ")
if v:
print(f"\n' i'm ' {final=}")
if v:
print(f"\nreturned repr(final)={repr(final)}\n\n---end verbose capitalise_sentence\n")
return final
def clean_beginning_string(string_input, v=False):
if string_input not in [None, '', ' ', '-', ' - ']:
if v:
print(f"\n---\nclean_beginning_string processing {repr(string_input)}")
valid = False
for i in range(1,21): # run enough time
if valid == False: # run as long as 1st character is not alphabetical
first_letter = string_input[0]
if not first_letter.isalpha():
string_input = string_input[1:]
if v:
print(f"{string_input}")
else:
valid = True
else:
break # break loop once 1st character is alphabetical
# Capitalise
if not string_input[0].isupper():
string_output = string_input.replace(string_input[0], string_input[0].upper(), 1) # replace only first occurence of character with capital
else:
string_output = string_input
else:
string_output = string_input
if v:
print(f"{string_output=}")
return string_output
def clean_transcript(transcript):
global v
if v:
print(f"\n#{get_linenumber()} Transcript to clean:\n{repr(transcript)}\n")
### Create dict of replacements
if v:
print(f"\n#{get_linenumber()} Creating dict of replacements:\n")
replacements_file = 'replacements.txt'
replacements = {}
with open(replacements_file, 'r') as df:
lines = df.readlines()
for line in lines:
if not line.startswith('#'): # remove comments
# print("line: ", repr(line))
line_parts = line.split('|')
if v:
print(f"#{get_linenumber()} {line_parts=}")
replacements[line_parts[0]] = line_parts[1][:-1] # remove trailing \n
### Lowercase transcript / helps with replacement logic + clean basis for proper capitalisation
transcript = transcript.lower()
### Remove punctuation
if ',' in transcript:
transcript = transcript.replace(',', '')
if '.' in transcript:
transcript = transcript.replace('.', '')
# Replacements
if v:
print(f"\n#{get_linenumber()} Processing list of replacements:\n")
for k,value in replacements.items():
if v:
print(f"#{get_linenumber()} replacing {repr(k)} with {repr(value)}")
if k in transcript:
if value == '\\n':
transcript = transcript.replace(k, '\n')
else:
transcript = transcript.replace(k, value)
if v:
print(f"\n#{get_linenumber()} Processing by lines:\n")
if '\n' in transcript:
parts = transcript.split('\n')
output = []
for part in parts:
if v:
print(f"#{get_linenumber()} {part=}")
part = clean_beginning_string(part, v=v)
part = capitalise_sentence(part, v=v)
part = f"{part} " # add 2 trailing spaces for Markdown linebreaks
output.append(part)
final_output = "\n".join(output)
else:
final_output = clean_beginning_string(transcript, v=v)
# Final cleaning
if ' / ' in final_output:
final_output = final_output.replace(' / ', '/')
if ' .' in final_output:
final_output = final_output.replace(' .', '.')
if ' ,' in final_output:
final_output = final_output.replace(' ,', ',')
if ' ?' in final_output:
final_output = final_output.replace(' ?', '?')
if '??' in final_output:
final_output = final_output.replace('??', '?')
if ' :' in final_output:
final_output = final_output.replace(' :', ':')
if v:
print(f"\nTranscript cleaned:\n{final_output}\n")
with open(f"/Users/{USER}/Python/transcribee/processed/{uid}.txt", 'w') as file:
file.write(final_output)
return final_output
def add_to_voice_memos_txt(memo_transcript, uid, full_path, transcribe_language):
global v
publish_date = f"{uid[:4]}-{uid[4:6]}-{uid[6:8]}"
output = f"\n{full_path}\n{publish_date} | {transcribe_language}\n---\n{memo_transcript}\n\n"
with open(f'/Users/{USER}/Python/homee/voice-memos.txt', 'a') as f:
print(output, file=f)
def define_uid(run, folder_path, filename):
if run == "JustPressRecord":
parent_folder = root[len(folder_path) + 1:]
if v:
print(f"{parent_folder=}")
if 'icloud' in filename:
filename_root = filename[1:] # remove leading dot
else:
filename_root = filename[:-4]
uid = f"{parent_folder.replace('-','')}-{filename_root.replace('-','')}"
if v:
print(f"{uid=}")
if run == "Apple":
filename_root = filename[:-13]
if v:
print(f"{filename_root=}")
uid = filename_root.replace(' ','-')
if v:
print(f"{uid=}")
return uid
### FETCH RECORDINGS
count_recordings = 0
### List already transcribed files
already_transcribed = []
with open('log.txt', 'r') as df:
lines = df.readlines()
for line in lines:
if len(line) > 10: # lines with ERRORs
already_transcribed.append(line[:15]) # keep only the UID
else:
already_transcribed.append(line[:-1]) # -1 to remove trailing new line
if v:
print(f"Already transcribed UIDs:")
pp.pprint(already_transcribed)
print()
if run == 'JustPressRecord':
folder_path = f"/Users/{USER}/Library/Mobile Documents/iCloud~com~openplanetsoftware~just-press-record/Documents" # returns partly `.icloud` files
if run == 'Apple':
folder_path = f"/Users/{USER}/Library/Application Support/com.apple.voicememos/Recordings"
for root, dirs, files in os.walk(folder_path):
for filename in os.listdir(root):
if filename.endswith(".icloud"):
count_recordings += 1
separator() # prints separator lines for clarity
print(f"recording #{count_recordings} iCloud file: {filename} from {run} / SKIPPING\n")
uid = define_uid(run, folder_path, filename)
### Log
if uid not in already_transcribed:
if v:
print(f"Adding {uid} as iCloud to log.")
with open('log.txt', 'a') as f:
print(f"{uid} ICLOUD FILE", file=f)
break
if filename.endswith(".m4a"):
count_recordings += 1
separator() # prints separator lines for clarity
print(f"recording #{count_recordings} Processing {filename} from {run}\n")
print(f"{filename=}")
### Full Path
full_path = os.path.join(root, filename)
if v:
print(f"{full_path=}")
uid = define_uid(run, folder_path, filename)
### Process if not done already
if uid not in already_transcribed:
if count_to_do == 0:
print(f"\n#{get_linenumber()} NO count_to_do in line {line_count_to_do} / TESTING")
elif count_processed < count_to_do:
#### Defne copy_to_path for audio file but copy later (only once file processed)
copy_to_path = f"/Users/{USER}/Python/transcribee/files/{uid}.m4a"
# try:
transcribe_object = transcribe(full_path, uid) # returns namedtuple with `text` and `language`
if v:
f"#{get_linenumber()} {transcribe_object=}"
raw_transcribe = transcribe_object.text
if v:
f"#{get_linenumber()} {raw_transcribe=}"
transcribe_language = transcribe_object.language
if v:
f"#{get_linenumber()} {transcribe_language=}"
transcript = clean_transcript(raw_transcribe)
if v:
f"#{get_linenumber()} {transcript=}"
add_to_voice_memos_txt(transcript, uid, copy_to_path, transcribe_language)
### Log if successful
print(f"Adding {uid} to log.")
with open('log.txt', 'a') as f:
print(uid, file=f)
# except Exception as e:
# print(f"\n\nERROR {e} with {run} ID {uid}.")
# with open('log.txt', 'a') as f:
# print(f"{uid} ERROR {run}", file=f)
### Copy file to project folder /files now that everything is done
if v:
print(f"\nCOPYING FILE:")
print(f"from {full_path}")
print(f"to {copy_to_path}\n")
shutil.copy2(full_path, copy_to_path)
count_processed += 1
already_transcribed.append(uid)
else:
print(f"\n{uid} already transcribed.")
count_already_transcribed += 1
Next:
- figure out how to trigger python script from hazel.
- Rename transcribee to transcriptee?
- Test recording with meeting recordings (tweak the export
.srtfunctions to add timings)
Question:
- can I feedback errors to Whisper for the AI to learn? 🤔
26 Sep 2022
Updated script, now as main function transcribe with parameters:
allruns all voice memos in selected folder and appends transcript to central text file (voice-memos.txt)<file_path>transcribes only given file and creates a.txtfile with same name in same folder
running automatically with Hazel
Working setup:
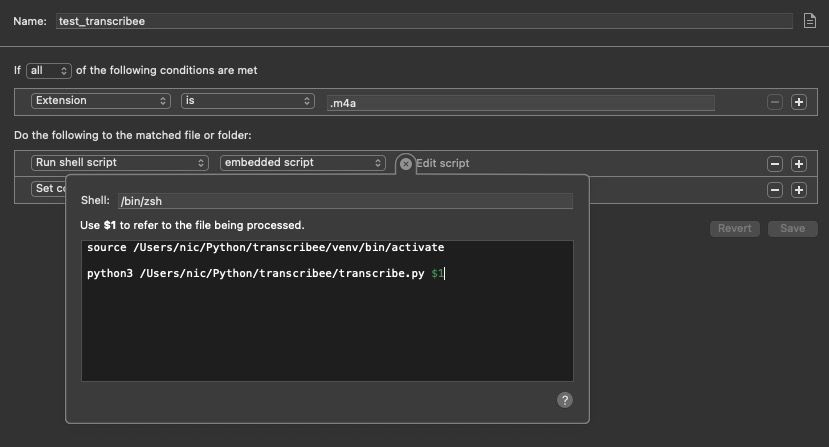
TODO: Alfred action on files
Final script
Implemented now:
- fully automated transcription of voice memos: takes 30s from end recording to transcript appearing in txt file
- dedicated
transcribefolder: any file dropped in it gets transcribed with a.txtfile of the same name in same folder.
# default boilerplate removed for brevity, see https://notes.nicolasdeville.com/python/boilerplate/
####################
# Transcribee
# https://notes.nicolasdeville.com/projects/transcribee
#### DEFAULT PARAMETERS
count_to_do = 100 # can be capped for tests
v = True # verbose flag / can be overridden as a function parameter to be passed
####
import whisper
import re
import shutil
from collections import namedtuple # to return transcript result as namedtuple
import os, os.path
from pathlib import Path
import sys
line_count_to_do = get_linenumber() - 6 # for referencing count_to_do line number in warning messages
count_recordings = 0
count_processed = 0
count_already_transcribed = 0
def separator(count=50, lines=3, symbol='='):
separator = f"{symbol * count}" + '\n'
separator = f"\n{separator * lines}"
print(separator)
def transcribe(file_path, uid):
global v
model = whisper.load_model("base")
response = model.transcribe(file_path)
text = response["text"]
language = response["language"]
transcript = namedtuple('Transcript', ['text', 'language'])
final = transcript(text=text, language=language)
# Archive raw
with open(f"/Users/{USER}/Python/transcribee/raw/{uid}.txt", 'w') as file:
file.write(f"{final.language}\n{final.text}")
if v:
print(f'\n#{get_linenumber()} transcript["text"] = {transcript.text}\n')
return final # namedtuple `transcript``: (transcript.text, transcript.language)
def capitalise_sentence(og_string, v=False):
if v:
print(f"\n---start verbose capitalise_sentence (deactivate with v=False)")
print(f"\n{og_string=}")
# lowercase everything
lower_s = og_string.lower()
if v:
print(f"\n{lower_s=}")
# start of string & acronyms
final = re.sub(r"(\A\w)|"+ # start of string
"(?<!\.\w)([\.?!] )\w|"+ # after a ?/!/. and a space,
# but not after an acronym
"\w(?:\.\w)|"+ # start/middle of acronym
"(?<=\w\.)\w", # end of acronym
lambda x: x.group().upper(),
lower_s)
if v:
print(f"\nstart_string {final=}")
# I exception
if ' i ' in final:
final = final.replace(' i ', ' I ')
if v:
print(f"\n' i ' {final=}")
if " i'm " in final:
final = final.replace(" i'm ", " I'm ")
if v:
print(f"\n' i'm ' {final=}")
if v:
print(f"\nreturned repr(final)={repr(final)}\n\n---end verbose capitalise_sentence\n")
return final
def clean_beginning_string(string_input, v=False):
if string_input not in [None, '', ' ', '-', ' - ']:
if v:
print(f"\n---\nclean_beginning_string processing {repr(string_input)}")
valid = False
for i in range(1,21): # run enough time
if valid == False: # run as long as 1st character is not alphabetical
first_letter = string_input[0]
if not first_letter.isalpha():
string_input = string_input[1:]
if v:
print(f"{string_input}")
else:
valid = True
else:
break # break loop once 1st character is alphabetical
# Capitalise
if not string_input[0].isupper():
string_output = string_input.replace(string_input[0], string_input[0].upper(), 1) # replace only first occurence of character with capital
else:
string_output = string_input
else:
string_output = string_input
if v:
print(f"{string_output=}")
return string_output
def clean_transcript(transcript, uid):
global v
if v:
print(f"\n#{get_linenumber()} Transcript to clean:\n{repr(transcript)}\n")
### Create dict of replacements
if v:
print(f"\n#{get_linenumber()} Creating dict of replacements:\n")
replacements_file = f"/Users/{USER}/Python/transcribee/replacements.txt"
replacements = {}
with open(replacements_file, 'r') as df:
lines = df.readlines()
for line in lines:
if not line.startswith('#'): # remove comments
# print("line: ", repr(line))
line_parts = line.split('|')
if v:
print(f"#{get_linenumber()} {line_parts=}")
replacements[line_parts[0]] = line_parts[1][:-1] # remove trailing \n
### Lowercase transcript / helps with replacement logic + clean basis for proper capitalisation
transcript = transcript.lower()
### Remove punctuation
if ',' in transcript:
transcript = transcript.replace(',', '')
if '.' in transcript:
transcript = transcript.replace('.', '')
# Replacements
if v:
print(f"\n#{get_linenumber()} Processing list of replacements:\n")
for k,value in replacements.items():
if v:
print(f"#{get_linenumber()} replacing {repr(k)} with {repr(value)}")
if k in transcript:
if value == '\\n':
transcript = transcript.replace(k, '\n')
else:
transcript = transcript.replace(k, value)
if v:
print(f"\n#{get_linenumber()} Processing by lines:\n")
if '\n' in transcript:
parts = transcript.split('\n')
output = []
for part in parts:
if v:
print(f"#{get_linenumber()} {part=}")
part = clean_beginning_string(part, v=v)
part = capitalise_sentence(part, v=v)
part = f"{part} " # add 2 trailing spaces for Markdown linebreaks
output.append(part)
final_output = "\n".join(output)
else:
final_output = clean_beginning_string(transcript, v=v)
# Final cleaning
if ' / ' in final_output:
final_output = final_output.replace(' / ', '/')
if ' .' in final_output:
final_output = final_output.replace(' .', '.')
if ' ,' in final_output:
final_output = final_output.replace(' ,', ',')
if ' ?' in final_output:
final_output = final_output.replace(' ?', '?')
if '??' in final_output:
final_output = final_output.replace('??', '?')
if ' :' in final_output:
final_output = final_output.replace(' :', ':')
if ' ai ' in final_output:
final_output = final_output.replace(' ai ', ' AI ')
if v:
print(f"\nTranscript cleaned:\n{final_output}\n")
with open(f"/Users/{USER}/Python/transcribee/processed/{uid}.txt", 'w') as file:
file.write(final_output)
return final_output
def add_to_voice_memos_txt(memo_transcript, uid, full_path, transcribe_language):
global v
publish_date = f"{uid[:4]}-{uid[4:6]}-{uid[6:8]}"
output = f"\n{full_path}\n{publish_date} | {transcribe_language}\n---\n{memo_transcript}\n\n"
with open(f'/Users/{USER}/Python/homee/voice-memos.txt', 'a') as f:
print(output, file=f)
def define_uid(run, full_path, filename):
if v:
print(f"\n{get_linenumber()} starting define_uid with:\n{run=}\n{full_path=}\n{filename=}\n")
if run == "JustPressRecord":
path_parts = Path(full_path).parts
parent_folder = path_parts[-2]
if v:
print(f"{parent_folder=}")
if 'icloud' in filename:
filename_root = filename[1:] # remove leading dot
else:
filename_root = filename[:-4]
uid = f"{parent_folder.replace('-','')}-{filename_root.replace('-','')}"
if v:
print(f"{uid=}")
if run == "Apple":
filename_root = filename[:-13]
if v:
print(f"{filename_root=}")
uid = filename_root.replace(' ','-')
if v:
print(f"{uid=}")
return uid
def processing(file='', v=v):
global count_recordings
global count_processed
global count_already_transcribed
if file == 'all':
"""
FETCH ALL RECORDINGS
from known Voice Memo folders
"""
print(f"\n\nPROCESSING ALL RECORDINGS\n\n")
### List already transcribed files
already_transcribed = []
with open(f'/Users/{USER}/Python/transcribee/log.txt', 'r') as df:
lines = df.readlines()
for line in lines:
if len(line) > 10: # lines with ERRORs
already_transcribed.append(line[:15]) # keep only the UID
else:
already_transcribed.append(line[:-1]) # -1 to remove trailing new line
if v:
print(f"Already transcribed UIDs:")
pp.pprint(already_transcribed)
print()
folder_paths = [
f"/Users/{USER}/Library/Mobile Documents/iCloud~com~openplanetsoftware~just-press-record/Documents", # JustPressRecord / returns partly `.icloud` files
f"/Users/{USER}/Library/Application Support/com.apple.voicememos/Recordings", # Apple Voice Memos
]
for folder_path in folder_paths:
if 'apple.voicememos' in folder_path:
run = 'Apple'
elif 'just-press-record' in folder_path:
run = 'JustPressRecord'
for root, dirs, files in os.walk(folder_path):
for filename in os.listdir(root):
if filename.endswith(".icloud"):
count_recordings += 1
separator() # prints separator lines for clarity
print(f"recording #{count_recordings} iCloud file: {filename} from {run} / SKIPPING\n")
uid = define_uid(run, folder_path, filename)
### Log
if uid not in already_transcribed:
if v:
print(f"Adding {uid} as iCloud to log.")
with open(f'/Users/{USER}/Python/transcribee/log.txt', 'a') as f:
print(f"{uid} ICLOUD FILE", file=f)
break
if filename.endswith(".m4a"):
count_recordings += 1
separator() # prints separator lines for clarity
print(f"recording #{count_recordings} Processing {filename} from {run}\n")
print(f"{filename=}")
### Full Path
full_path = os.path.join(root, filename)
if v:
print(f"{full_path=}")
uid = define_uid(run, full_path, filename)
### Process if not done already
if uid not in already_transcribed:
if count_to_do == 0:
print(f"\n#{get_linenumber()} NO count_to_do in line {line_count_to_do} / TESTING")
elif count_processed < count_to_do:
#### Define copy_to_path for audio file but copy later (only once file processed)
copy_to_path = f"/Users/{USER}/Python/transcribee/files/{uid}.m4a"
# try:
transcribe_object = transcribe(full_path, uid) # returns namedtuple with `text` and `language`
if v:
f"#{get_linenumber()} {transcribe_object=}"
raw_transcribe = transcribe_object.text
if v:
f"#{get_linenumber()} {raw_transcribe=}"
transcribe_language = transcribe_object.language
if v:
f"#{get_linenumber()} {transcribe_language=}"
transcript = clean_transcript(raw_transcribe, uid)
if v:
f"#{get_linenumber()} {transcript=}"
add_to_voice_memos_txt(transcript, uid, copy_to_path, transcribe_language)
### Log if successful
print(f"Adding {uid} to log.")
with open(f'/Users/{USER}/Python/transcribee/log.txt', 'a') as f:
print(uid, file=f)
# except Exception as e:
# print(f"\n\nERROR {e} with {run} ID {uid}.")
# with open(f'/Users/{USER}/Python/transcribee/log.txt', 'a') as f:
# print(f"{uid} ERROR {run}", file=f)
### Copy file to project folder /files now that everything is done
if v:
print(f"\nCOPYING FILE:")
print(f"from {full_path}")
print(f"to {copy_to_path}\n")
shutil.copy2(full_path, copy_to_path)
count_processed += 1
already_transcribed.append(uid)
else:
print(f"\n{uid} already transcribed.")
count_already_transcribed += 1
elif file.startswith('/Users/'):
"""
PROCESS A SINGLE RECORDING
"""
print(f"\n\nPROCESSING {file}\n\n")
filepath_parts = Path(file).parts
if v:
print(f"{get_linenumber()} {filepath_parts=} {type(filepath_parts)}")
uid = filepath_parts[-1]
if v:
print(f"{get_linenumber()} {uid=}")
copy_to_path = os.path.abspath(os.path.join(file, os.pardir))
if v:
print(f"{get_linenumber()} {copy_to_path=}")
# try:
transcribe_object = transcribe(file, uid) # returns namedtuple with `text` and `language`
if v:
f"#{get_linenumber()} {transcribe_object=}"
raw_transcribe = transcribe_object.text
if v:
f"#{get_linenumber()} {raw_transcribe=}"
transcribe_language = transcribe_object.language
if v:
f"#{get_linenumber()} {transcribe_language=}"
transcript = clean_transcript(raw_transcribe, uid)
if v:
f"#{get_linenumber()} {transcript=}"
output = f"\n{file}\ntranscribed: {ts_db} | {transcribe_language}\n---\n{transcript}\n\n"
with open(f"{copy_to_path}/{uid}.txt", 'w') as f:
print(output, file=f)
# except:
else:
print(f"{get_linenumber()} WRONG parameter passed. Should be empty or starting with /Users/")
########################################################################################################
if __name__ == '__main__':
print()
processing(file=sys.argv[1])
# default boilerplate removed for brevity, see https://notes.nicolasdeville.com/python/boilerplate/
with replacements.txt now:
nick, note|Nic Note
nicknote|Nic Note
nick note|Nic Note
nick, note|Nic Note
you line|\n
new line|\n
you line|\n
new line|\n
your line|\n
dash|-
full stop|.
four step|.
full step|.
full-step|.
full-stop|.
for stop|.
forstub|.
for step|.
fullstop|.
fostop|.
false stop|.
false top|.
forstup|.
come up|,
call in|:
colin|:
colon|:
commons|comments
c | see
We were|Reword
Salves|Sales
cells|Sales
Node|Note
.|.
,|,
?|?
,|,
question mark|?
come out|,
comer|,
opposed up|.
full-stop|.
on 24|ON24
second|2nd
comma|,
thoughtslash|/
forward slash |/
false-lash|/
we were|reword
smiley face|😁
open quote|"
close quote|"
# every input lower case
# always leave an empty line at the end
Optimisations
01 Sep 2024
Working on improvements:
- faster
- with formatted output
- with summary at the end
Updated Whisper's library, which broke my script :/
Starting from scratch (blank page), and running speed tests first.
Test video file: 49mns
Testing models:
Base - 3mns
Small - 30mns & gibberish
Medium - 24mns & good result
Large - 97mns (need to analyse quality difference)
Potential optimisations:
1. Use a Conda Environment with Metal Support
Whisper relies heavily on PyTorch for its operations, and PyTorch has a version optimized for Apple Silicon (M1/M2) that can leverage Apple’s Metal Performance Shaders. This can significantly speed up model inference. You should install PyTorch with Metal support via Conda.
First, install Conda if you haven’t already. Then, create a new environment with PyTorch optimized for M1/M2:
# Install Miniforge (Conda variant optimized for Apple Silicon)
curl -L https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh -o Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
# Create a new environment with PyTorch and dependencies
conda create -n whisper-metal python=3.9
conda activate whisper-metal
# Install PyTorch with Metal backend
conda install pytorch torchvision torchaudio -c pytorch-nightly -c conda-forge
Installed:
To activate this environment, use:
micromamba activate /Users/nic/Python/transcribee/miniforge3
Or to execute a single command in this environment, use:
micromamba run -p /Users/nic/Python/transcribee/miniforge3 mycommand
installation finished.
WARNING:
You currently have a PYTHONPATH environment variable set. This may cause
unexpected behavior when running the Python interpreter in Miniforge3.
For best results, please verify that your PYTHONPATH only points to
directories of packages that are compatible with the Python interpreter
in Miniforge3: /Users/nic/Python/transcribee/miniforge3
Do you wish to update your shell profile to automatically initialize conda?
This will activate conda on startup and change the command prompt when activated.
If you'd prefer that conda's base environment not be activated on startup,
run the following command when conda is activated:
conda config --set auto_activate_base false
You can undo this by running `conda init --reverse $SHELL`? [yes|no]
2. Leverage the fp16 Precision
Using fp16 (half-precision floating point) instead of fp32 (full precision) can speed up inference significantly.
import whisper
def transcribe_file(file_path):
model = whisper.load_model("medium")
options = whisper.DecodingOptions(fp16=True) # Force fp16 precision
result = model.transcribe(file_path, options=options)
transcript = result['text']
print(f"\n\nTranscript:\n{transcript}\n\n")
return transcript
if __name__ == '__main__':
transcribe_file('/path/to/file.mp4')
3. Segmented Transcription
If the model still takes too long to process long files, consider breaking the audio into smaller segments. This would parallelize the transcription process if you use a multiprocessing approach.
import whisper
import multiprocessing
from pydub import AudioSegment
def transcribe_segment(segment):
model = whisper.load_model("medium")
result = model.transcribe(segment)
return result['text']
def transcribe_file(file_path, segment_length=300):
audio = AudioSegment.from_file(file_path)
segments = [audio[i:i + segment_length * 1000] for i in range(0, len(audio), segment_length * 1000)]
with multiprocessing.Pool(processes=multiprocessing.cpu_count()) as pool:
results = pool.map(transcribe_segment, segments)
transcript = ' '.join(results)
print(f"\n\nTranscript:\n{transcript}\n\n")
return transcript
if __name__ == '__main__':
transcribe_file('/path/to/file.mp4')
WhisperX
17 Nov 2024
WhisperX is an enhanced variant of OpenAI’s Whisper model.
It uses a new architecture that leverages the latest advancements in deep learning and hardware acceleration to provide faster and more accurate transcription results.
But it also includes speaker diarization, punctuation, and formatting options to make the transcripts more readable and useful.
Here is what I have so far:
# IMPORTS
import torch
import whisperx
import os
from pathlib import Path
from tqdm import tqdm
# GLOBALS
troubleshoot = True
model_size = "large-v3"
"""
ValueError: Invalid model size 'turbo', expected one of:
tiny.en in 49mns / WRONG
tiny in 49mns
base.en
base
small.en
small
medium.en
medium in 53mns / 13mns
large-v1
large-v2
large-v3 in 58mns
large
distil-large-v2
distil-medium.en
distil-small.en
"""
print(f"\n\n>>> PROCESSING AS SINGLE RECORDING WITH {model_size}\n\n")
# Add after other globals
verbose = True
# FUNCTIONS
def transcribe_with_diarization(video_path, auth_token):
"""
Transcribe video with speaker diarization using WhisperX
Args:
video_path: Path to video file
auth_token: HuggingFace authentication token
Returns:
List of transcribed segments with speaker labels
"""
step_start = time.time()
global model_size, verbose
if verbose:
print(f"\nStarting transcription of {video_path}")
device = "mps" if torch.cuda.is_available() else "cpu"
# Load WhisperX model
model = whisperx.load_model(model_size, device, compute_type="float32")
if verbose:
print(f"ℹ️ Model loaded in {round(time.time() - step_start, 2)}s")
# Load audio
step_start = time.time()
audio = whisperx.load_audio(video_path)
if verbose:
print(f"ℹ️ Audio loaded in {round(time.time() - step_start, 2)}s")
# Transcribe
step_start = time.time()
result = model.transcribe(audio, batch_size=32)
if verbose:
print(f"ℹ️ Transcription completed in {round(time.time() - step_start, 2)}s")
# Diarization
step_start = time.time()
diarize_model = whisperx.DiarizationPipeline(use_auth_token=auth_token, device=device)
diarize_segments = diarize_model(audio)
if verbose:
print(f"ℹ️ Diarization completed in {round(time.time() - step_start, 2)}s")
# Align speakers
step_start = time.time()
result = whisperx.assign_word_speakers(diarize_segments, result)
if verbose:
print(f"ℹ️ Speaker alignment completed in {round(time.time() - step_start, 2)}s")
return result["segments"]
# MAIN
video_dir = Path("videos")
output_dir = Path("videos")
output_dir.mkdir(exist_ok=True)
# # Process all video files in directory
# for video_file in video_dir.glob("*.mp4"):
# Get all video files
video_files = list(video_dir.glob("*.mp4"))
# Process each video file that doesn't have a transcript
for video_file in video_files:
# Check if any transcript exists (any .txt file starting with video filename)
# transcript_pattern = f"{video_file.stem}*.txt"
transcript_pattern = f"{video_file.stem}_transcript.txt"
existing_transcripts = list(output_dir.glob(transcript_pattern))
if existing_transcripts:
if verbose:
print(f"\n❌ Skipping {video_file.name} - transcript already exists\n")
continue
file_start = time.time()
print(f"\n\n=============== ℹ️ Processing {video_file.name}...\n")
# Transcribe with diarization
segments = transcribe_with_diarization(str(video_file), HF_AUTH_TOKEN)
# if troubleshoot:
# print(f"\n\n🔍 Segments:")
# pp.pprint(segments)
# print(f"\n\n")
# Track the previous speaker
previous_speaker = None
# Write output to file
if troubleshoot:
output_file = output_dir / f"{video_file.stem}_transcript_{model_size}.txt"
else:
output_file = output_dir / f"{video_file.stem}_transcript.txt"
with open(output_file, "w", encoding="utf-8") as f:
for segment in segments:
current_speaker = segment.get("speaker", "UNKNOWN")
text = segment["text"]
# start = segment["start"]
# end = segment["end"]
# f.write(f"[{speaker}] ({start:.2f}s - {end:.2f}s): {text}\n")
if current_speaker != previous_speaker:
f.write(f"\n[{current_speaker}] {text}")
previous_speaker = current_speaker
else:
f.write(f" {text}")
print(f"\n\n✅ Transcript saved to {output_file}\n\n")
if verbose:
print(f"Total processing time for {video_file.name}: {round(time.time() - file_start, 2)}s")
outputs, eg:
[SPEAKER_01] Lorem ipsum dolor sit amet, consectetur adipiscing elit.
[SPEAKER_02] Quisque volutpat condimentum velit.
[SPEAKER_04] Sed nisi. Nulla quis sem at nibh elementum imperdiet.
[SPEAKER_02] Nulla facilisi. Phasellus ultrices nulla quis nibh.
Issues
25 Mar 2025
Using Whisper or WhisperX, having the issues of too many words max per caption/timestamp.

Try this library to help fix? (but not maintained in 2 years)

search code: recordee