
15 Jul 2022
Goals:
- remind myself of past great movies and rewatch them
- guide the lifetime movies journey of my kids
- structure better my watch time (great movies to watch rather than random-Netflixing)
- tinker with TMDB API and create an effective workflow
Reference: 787,956 Movies on TMDB.
17 Jul 2022
Steps:
- add selected movies to a private list on TMDB !python/tmdb-api
- fetch data from TMDB into Grist spreadsheet !apps/grist for movie management
- generate Markdown files for this site !python/library-pelican
24 Jul 2022
Download private list from TMDB, add to Grist for management and prepare for upload to this site
TMDB list up and running with ~500 movies to start with:
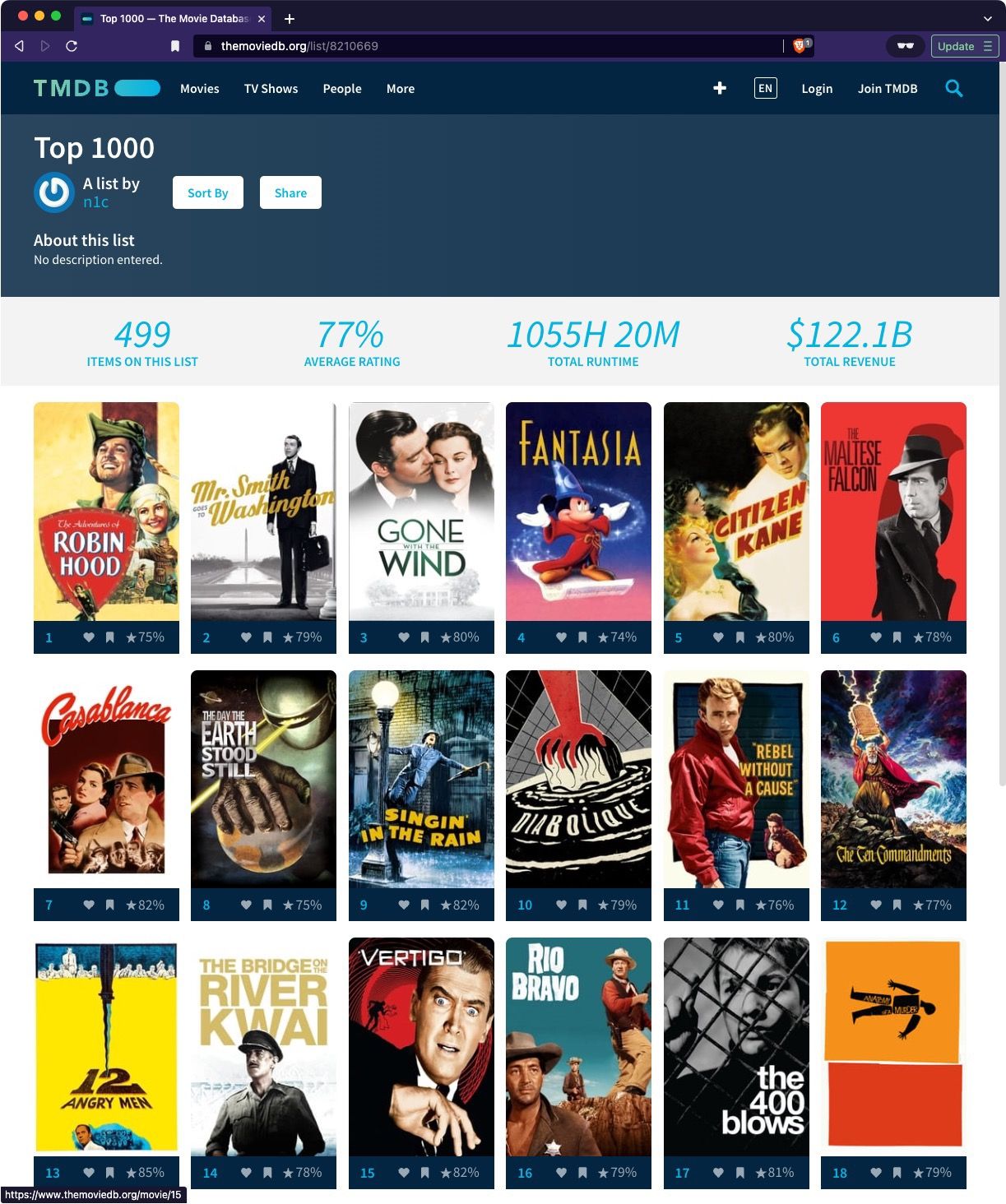
Working code, including adding to Grist for management (single source of truth):
import requests
import urllib.request
from slugify import slugify
tmdb_api_key = os.getenv("TMDB_API_KEY")
tmdb_v4_token = os.getenv("TMDB_V4_TOKEN")
grist_movies_doc_id = grist_PE.get_grist_movies_doc_id()
grist_api_key = grist_PE.get_grist_api_key()
my_top_1000_list_id = 8210669
existing_movies_tmdb_ids = grist_PE.get_movies_tmdb_ids()
# print(f"{existing_movies_tmdb_ids=}")
print(f"{len(existing_movies_tmdb_ids)} movies in DB.\n")
count = 0
count_added = 0
total_pages = 1
# add logic to loop through all the pages
my_1000_url = f"https://api.themoviedb.org/4/list/{my_top_1000_list_id}?page=1&api_key={tmdb_api_key}"
res_list = requests.get(my_1000_url).json()
# returns dict with 19 fields:
# average_rating
# backdrop_path
# comments
# created_by
# description
# id
# iso_3166_1
# iso_639_1
# name
# object_ids
# page
# poster_path
# public
# results
# revenue
# runtime
# sort_by
# total_pages
# total_results
# pp.pprint(m)
# the object_ids object includes the list of all movie ids in my list. Will be using that.
for m in res_list['object_ids']:
count += 1
# print(f"{m=}") # m is a string like 'movie:100' (print res_list['object_ids'] to check), so need to remove first 6 characters to grab the movie id.
movie_id = m[6:] #
# print(f"{movie_id=}")
if int(movie_id) not in existing_movies_tmdb_ids:
# print(f"New movie: processing...")
movie_url = f"https://api.themoviedb.org/3/movie/{movie_id}?api_key={tmdb_api_key}"
res_movie = requests.get(movie_url).json()
title = res_movie["title"]
slug = slugify(title)
original_language = res_movie["original_language"]
original_title = res_movie["original_title"]
tagline = res_movie["tagline"]
budget = res_movie["budget"]
tmdb_id = res_movie["id"]
imdb_id = res_movie["imdb_id"]
overview = res_movie["overview"]
release_date = res_movie["release_date"]
revenue = res_movie["revenue"]
runtime = res_movie["runtime"]
poster_path = f"https://image.tmdb.org/t/p/original{res_movie['poster_path']}"
poster_path_w154 = f"https://image.tmdb.org/t/p/w154{res_movie['poster_path']}"
print(f"\n{count} adding {title=}")
# print(f"{original_language=}")
# print(f"{original_title=}")
# print(f"{tagline=}")
# print(f"{budget=}")
# print(f"{tmdb_id=}")
# print(f"{imdb_id=}")
# print(f"{overview=}")
# print(f"{release_date=}")
# print(f"{revenue=}")
# print(f"{runtime=}")
# print(f"{poster_path=}")
# Save poster original size locally
poster_filepath = f"/Users/nic/Pictures/movie_posters/{slug}.jpg"
# Save poster small size locally for easier upload to Grist + notes publishing later
poster_small_filepath = f"/path/to/folder/poster_{slug}_w154.jpg"
urllib.request.urlretrieve(f"{poster_path}", poster_filepath)
urllib.request.urlretrieve(f"{poster_path_w154}", poster_small_filepath)
# Upload small poster to Grist
response = requests.post(
f"https://docs.getgrist.com/api/docs/{grist_movies_doc_id}/attachments",
files={"upload": open(poster_small_filepath, "rb")},
headers={"Authorization": f"Bearer {grist_api_key}"},
)
attachment_id = response.json()[0]
# print(f"{attachment_id=}") # to check
poster_file = ["L", attachment_id]
# print(f"{poster_file=}") # to check
grist_PE.Movies.add_records('Master', [
{ 'title': title,
'slug': slug,
'og_title': original_title,
'language': original_language,
'tagline': tagline,
'budget': budget,
'tmdb_id': tmdb_id,
'imdb_id': imdb_id,
'overview': overview,
'release_date': release_date,
'revenue': revenue,
'runtime': runtime,
'poster': poster_file,
}
])
count_added += 1
print()
# else:
# print(f"{count} {movie_id=} already in Grist.")
print(f"\nCount ADDED: {count_added}")
First run with 492 movies in my list on TMDB:
Result:
-------------------------------
tmdb_1000.py
Count = 492
-------------------------------
tmdb_1000.py finished in 13.281666666666666 minutes.
Seems to run well.
Running the script from now on (runs in 5s-ish) will add to Grist only the new additions in TMDB.
Next steps:
- Add new movies to TMDB & refine workflow as needed.
- Write code to generate movie library list for this site.
add new movies
First hurdle: no way to see on TMDB's Top Rated page which movies are already in my list. Impossibly painful to continue adding movies like that :(
Streamline the process by fetching movies from TMDB's Top Rated list (https://www.themoviedb.org/movie/top-rated) and filtering out:
- those already in my list
- movies where original language is not
en,frorde(by large most movies I have seen)
Adding them to Grist where I can easily select which ones to add to my list, and update my list on TMDB back via API (using TMDB ID).
Working code:
####################
# Getting Top Rated movied from TMDB, filtering out:
# - those already in my list
# - movies where original language is not `en`, `fr` or `de` (only movies I have seen)
import requests
import urllib.request
from slugify import slugify
tmdb_api_key = os.getenv("TMDB_API_KEY")
tmdb_v4_token = os.getenv("TMDB_V4_TOKEN")
grist_movies_doc_id = grist_PE.get_grist_movies_doc_id()
grist_api_key = grist_PE.get_grist_api_key()
count = 0
count_added = 0
existing_movies_tmdb_ids = grist_PE.get_movies_tmdb_ids()
print(f"{len(existing_movies_tmdb_ids)} movies in my DB.\n")
existing_top_rated_movies_tmdb_ids = grist_PE.get_top_rated_movies_tmdb_ids()
print(f"{len(existing_top_rated_movies_tmdb_ids)} Top Rated movies in DB.\n")
total_pages = requests.get(f"https://api.themoviedb.org/3/movie/top_rated?page=1&api_key={tmdb_api_key}").json()['total_pages']
# total_pages = 3 # for tests purposes
print(f"{total_pages} pages of Top Rated movies on TMDB.\n")
for page in range(1, total_pages):
top_rated_movies_url = f"https://api.themoviedb.org/3/movie/top_rated?page={page}&api_key={tmdb_api_key}"
res_list = requests.get(top_rated_movies_url).json()
# pp.pprint(res_list)
for m in res_list['results']:
# returns dict with 4 fields:
# page: int
# results: list of dicts with 14 fields per movie, 20 movies per page:
# adult
# backdrop_path
# genre_ids
# id
# original_language
# original_title
# overview
# popularity
# poster_path
# release_date
# title
# video
# vote_average
# vote_count
# total_pages: int / 507
# total_results: int / 10127
# the results object includes the list of all movies. Will be using that.
movie_id = m["id"]
if int(movie_id) not in existing_movies_tmdb_ids:
if int(movie_id) not in existing_top_rated_movies_tmdb_ids:
original_language = m["original_language"]
if original_language in ['en', 'de', 'fr']:
movie_url = f"https://api.themoviedb.org/3/movie/{movie_id}?api_key={tmdb_api_key}"
res_movie = requests.get(movie_url).json()
title = m["title"]
slug = slugify(title)
original_title = m["original_title"]
tmdb_id = m["id"]
tmdb_url = f"https://www.themoviedb.org/movie/{movie_id}-{slug}" # adding the TMDB URL for easy cheching
overview = m["overview"]
release_date = m["release_date"]
poster_path_w154 = f"https://image.tmdb.org/t/p/w154{res_movie['poster_path']}" # only need small version for check purposes
print(f"{title=}")
print(f"{original_language=}")
print(f"{original_title=}")
print(f"{tmdb_id=}")
print(f"{original_language=}")
print(f"{release_date=}")
print(f"{poster_path_w154=}")
print()
# => when importing selected movies to Master table (Top 1000), need to use the https://api.themoviedb.org/3/movie/{movie_id}?api_key={tmdb_api_key} endpoint for each to get missing fields
# Save poster small size locally for easier upload to Grist
poster_filepath = f"/Users/nic/Pictures/movie_posters/154/{slug}_154.jpg"
urllib.request.urlretrieve(poster_path_w154, poster_filepath)
# Upload small poster to Grist
response = requests.post(
f"https://docs.getgrist.com/api/docs/{grist_movies_doc_id}/attachments",
files={"upload": open(poster_filepath, "rb")},
headers={"Authorization": f"Bearer {grist_api_key}"},
)
attachment_id = response.json()[0]
# print(f"{attachment_id=}") # to check
poster_file = ["L", attachment_id]
# print(f"{poster_file=}") # to check
grist_PE.Movies.add_records('TopRated', [
{ 'title': title,
'og_title': original_title,
'language': original_language,
'tmdb_url': tmdb_url,
'tmdb_id': tmdb_id,
'release_date': release_date,
'poster': poster_file,
}
])
count_added += 1
print()
print(f"\nCount ADDED: {count_added}")
First run with 507 pages of top-rated movies on TMDB:
Result:
8,118 movies added.
Script failed though on page 501/507. Missing a try/except statement. Seems to be API limitation at 10k records? (500 * 20).
add movies from top rated list on Grist to my TMDB list
25 Jul 2022
struggling to authenticate to add/delete movies from my TMDB list.
Asked for help: https://www.themoviedb.org/talk/62de52250d9f5a0067b7fb72
Get back to it later...
adding missing director for each movie in Grist (data point not available from top_rated or list)
Working code, adding to Grist directly !apps/grist :
from dotenv import load_dotenv
load_dotenv()
import grist_PE # my own module to add to Grist
tmdb_api_key = os.getenv("TMDB_API_KEY")
print(f"\n{tmdb_api_key=}")
from tmdbv3api import TMDb, Movie, Person
tmdb = TMDb()
tmdb.api_key = tmdb_api_key
tmdb.language = 'en'
tmdb.debug = True
def director_by_movie_id(movie_id): # returns list of strings/directors
list_directors = []
movie = Movie()
movie_title = movie.details(movie_id)['title']
m = movie.credits(movie_id)
for crew in m.crew: # list of dict
if crew['job'] == 'Director':
list_directors.append(crew['name'])
print(f"Checked {movie_title}: {' '.join(list_directors)}")
return list_directors
top_1000_data = grist_PE.Movies.fetch_table('Master')
print(f"{len(top_1000_data)} movies in Grist Top 1000\n")
for m in top_1000_data:
count_row += 1
if m.director in [None, ""]:
count +=1
movie_id = m.tmdb_id
print(f"Processing {m.title} with ID {movie_id}")
director = director_by_movie_id(movie_id)[0] # fetch first one only in list / could be reworked with a join for multi-director movies
print(f"row{count_row} #{count} updating {m.title}")
grist_PE.Movies.update_records('Master', [
{'id': m.id,
'director': director,
}
])
code to generate movie library list for this site
Working script:
from dotenv import load_dotenv
load_dotenv()
import grist_PE
from operator import attrgetter # to sort namedtuple returned from Grist
from datetime import datetime
from slugify import slugify
top_1000_data = grist_PE.Movies.fetch_table('Master') # list of namedtuples
total = len(top_1000_data)
print(f"{total} movies in Grist Top 1000\n")
today = datetime.now()
date_today = today.strftime('%Y-%m-%d')
total_runtime = 0
output = ''
top_1000_data_sorted_by_release_date = sorted(top_1000_data, key=attrgetter('release_date'))
for m in top_1000_data_sorted_by_release_date:
count_row += 1
if m.delete == False:
count += 1
poster_path = f"<img class=\"screenshot\" src=\"https://ik.imagekit.io/vhucnsp9j1u/images/movies/poster_{m.slug}_w154.jpg\" alt=\"{m.slug}\"/>"
title = m.title
slug = slugify(title)
director = m.director
year = date = datetime.utcfromtimestamp(m.release_date).year #<class 'datetime.datetime'> 2019-02-07 00:00:00
tagline = m.tagline
rating = "⭐️" * m.rating
total_runtime += m.runtime
tmdb_url = f"https://www.themoviedb.org/movie/{m.tmdb_id}-{slug}"
output = f"{output}\n{poster_path} | <a href=\"{tmdb_url}\" target=\"_blank\">{title}</a> | {director} | {year} | {tagline} | {rating} | "
# Adding the header at the end to ensure proper movie count
header = f"Title: My Top 1,000 Movies \nSummary: an ongoing project...\n\n!projects/1000-movies \n\n{count} movies so far, for a total runtime of {int(total_runtime / 60)}h or {round(((total_runtime / 60) / 24), 1)} days...\n\nposter | title | director | year | tagline | rating |\n---|---|---|---|---|---|"
output = f"{header} {output} \n\nData & images from TMDB: <a href=\"https://www.themoviedb.org/\" target=\"_blank\"><img src=\"https://ik.imagekit.io/vhucnsp9j1u/images/logo_tmdb.svg\" alt=\"logo_tmdb.svg\"/> </a>"
with open(f"notes/content/articles/movies/1000.md", 'w') as file:
file.write(output)
Output:
Title: My Top 1,000 Movies
Summary: an ongoing project...
!projects/1000-movies
445 movies so far, for a total runtime of 945h or 39.4 days...
poster | title | director | year | tagline | rating |
---|---|---|---|---|---|
<img class="screenshot" src="https://ik.imagekit.io/vhucnsp9j1u/images/movies/poster_the-adventures-of-robin-hood_w154.jpg" alt="the-adventures-of-robin-hood"/> | <a href="https://www.themoviedb.org/movie/10907-the-adventures-of-robin-hood" target="_blank">The Adventures of Robin Hood</a> | Michael Curtiz | 1938 | Excitement... Danger... Suspense... as this classic adventure story sweeps across the screen! | ⭐️⭐️⭐️ |
<img class="screenshot" src="https://ik.imagekit.io/vhucnsp9j1u/images/movies/poster_mr-smith-goes-to-washington_w154.jpg" alt="mr-smith-goes-to-washington"/> | <a href="https://www.themoviedb.org/movie/3083-mr-smith-goes-to-washington" target="_blank">Mr. Smith Goes to Washington</a> | Frank Capra | 1939 | Romance, drama, laughter and heartbreak... created out of the very heart and soil of America! | ⭐️⭐️⭐️⭐️ |
<img class="screenshot" src="https://ik.imagekit.io/vhucnsp9j1u/images/movies/poster_gone-with-the-wind_w154.jpg" alt="gone-with-the-wind"/> | <a href="https://www.themoviedb.org/movie/770-gone-with-the-wind" target="_blank">Gone with the Wind</a> | Victor Fleming | 1939 | The greatest romance of all time! | ⭐️⭐️⭐️ |
Converted to HTML with Pelican !python/library-pelican:
Nic Note: My Top 1,000 Movies 😁
add movies from top rated list on Grist to my TMDB list
27 Jul 2022
Unable to solve authentication issue (see above).
Workaround: add movies from Grist "Top Rated" to Grist "Master" directly - no need to update TMDB list thinking about it.
working script:
####################
# Fetching movie data from Grist "Top Rated" list to Grist Master / with dedupe
from datetime import datetime
import os
import time
start_time = time.time()
import sys
from dotenv import load_dotenv
load_dotenv()
import grist_PE
import pprint
pp = pprint.PrettyPrinter(indent=4)
print(f"{os.path.basename(__file__)} boilerplate loaded -----------")
print()
import requests
import urllib.request
from slugify import slugify
tmdb_api_key = os.getenv("TMDB_API_KEY")
print(f"\n{tmdb_api_key=}\n")
grist_movies_doc_id = grist_PE.get_grist_movies_doc_id()
grist_api_key = grist_PE.get_grist_api_key()
existing_movies_tmdb_ids = grist_PE.get_movies_tmdb_ids()
print(f"{len(existing_movies_tmdb_ids)} movies in DB.\n")
count_row = 0
count = 0
count_added = 0
# Boilerplate for director search
from tmdbv3api import TMDb, Movie, Person
tmdb = TMDb()
tmdb.api_key = tmdb_api_key
tmdb.language = 'en'
tmdb.debug = True
def director_by_movie_id(movie_id): # returns list of strings
list_directors = []
movie = Movie()
movie_title = movie.details(movie_id)['title']
m = movie.credits(movie_id)
for crew in m.crew: # list of dict
if crew['job'] == 'Director':
list_directors.append(crew['name'])
return list_directors
# TopRated data
movies_top_rated_data = grist_PE.Movies.fetch_table('TopRated')
print(f"{len(movies_top_rated_data)} movies in Grist TopRated\n")
for m in movies_top_rated_data:
count_row += 1
movie_id = m.tmdb_id
if int(movie_id) not in existing_movies_tmdb_ids:
if m.add_top_1000 == True or m.to_watch == True:
count += 1
movie_url = f"https://api.themoviedb.org/3/movie/{movie_id}?api_key={tmdb_api_key}"
res_movie = requests.get(movie_url).json()
title = res_movie["title"]
slug = slugify(title)
original_language = res_movie["original_language"]
original_title = res_movie["original_title"]
tagline = res_movie["tagline"]
budget = res_movie["budget"]
tmdb_id = res_movie["id"]
tmdb_url = f"https://www.themoviedb.org/movie/{movie_id}-{slug}"
imdb_id = res_movie["imdb_id"]
overview = res_movie["overview"]
release_date = res_movie["release_date"]
release_year = int(release_date[:4])
revenue = res_movie["revenue"]
runtime = res_movie["runtime"]
poster_path = f"https://image.tmdb.org/t/p/original{res_movie['poster_path']}"
poster_path_w154 = f"https://image.tmdb.org/t/p/w154{res_movie['poster_path']}"
director = director_by_movie_id(movie_id)[0]
print(f"\n{count} adding {title} by {director}")
# Save poster original size locally
poster_filepath = f"/path/to/folder/movie_posters/{slug}.jpg"
# Save poster small size locally for easier upload to Grist + notes publishing later
poster_small_filepath = f"/path/to/pelican/folder/notes/content/images/movies/poster_{slug}_w154.jpg"
urllib.request.urlretrieve(f"{poster_path}", poster_filepath)
urllib.request.urlretrieve(f"{poster_path_w154}", poster_small_filepath)
# Upload small poster to Grist
response = requests.post(
f"https://docs.getgrist.com/api/docs/{grist_movies_doc_id}/attachments",
files={"upload": open(poster_small_filepath, "rb")},
headers={"Authorization": f"Bearer {grist_api_key}"},
)
attachment_id = response.json()[0]
poster_file = ["L", attachment_id]
grist_PE.Movies.add_records('Master', [
{ 'title': title,
'slug': slug,
'og_title': original_title,
'language': original_language,
'tagline': tagline,
'budget': budget,
'tmdb_id': tmdb_id,
'imdb_id': imdb_id,
'overview': overview,
'release_date': release_date,
'release_year': release_year,
'revenue': revenue,
'runtime': runtime,
'poster': poster_file,
'tmdb_url': tmdb_url,
'director': director,
}
])
count_added += 1
print(f"\nCount ADDED: {count_added}")
########################################################################################################
if __name__ == '__main__':
print()
print()
print('-------------------------------')
print(f"{os.path.basename(__file__)}")
print()
print(f"count_row = {count_row}")
print(f"count = {count}")
print(f"count_added = {count_added}")
print()
print('-------------------------------')
run_time = round((time.time() - start_time), 1)
if run_time > 60:
print(f'{os.path.basename(__file__)} finished in {run_time/60} minutes.')
else:
print(f'{os.path.basename(__file__)} finished in {run_time}s.')
print()
result:
-------------------------------
add_from_grist_top_rated.py
count_row = 8118
count = 353
count_added = 353
-------------------------------
add_from_grist_top_rated.py finished in 12.32 minutes.