
29 Jun 2022
| Library resources | |
|---|---|
| PyPI | https://pypi.org/project/pelican/ |
| Github | https://github.com/getpelican/pelican |
| Documentation | https://docs.getpelican.com/en/latest/ |
My blog hosting journey: Wordpress > Ghost > Pelican (current)
My blog writing journey: limited :)
Started learning/using Pelican on 27th June 2022.
Migrated 29th June.
Install
in venv:
pip3 install "pelican[markdown]"
To render
29 Jun 2022 ~1.3s to run
24 Jul 2022 now 1.9s with 260 articles.
07 Sep 2022 now 3s with 320 articles.
Done: Processed 328 articles, 0 drafts, 5 hidden articles, 1 page, 0 hidden
pages and 0 draft pages in 3.01 seconds.
run once
in a Terminal window:
cdto project directory. venv/bin/activate(to activate Pelican, installed in venv)cdtonotesfolder (your name may vary)pelican
warnings
23 Sep 2022 now with 400+ notes, and a URL structure with redundant article slugs, eg:
books/libraryapps/library
or
books/deep-workoffice/deep-work
I have many warnings printed while publishing, which is annoying:
Trying this : https://docs.getpelican.com/en/latest/settings.html?highlight=warnings#logging.
with example:
import logging
LOG_FILTER = [(logging.WARN, 'TAG_SAVE_AS is set to False')]
Source code where the warning is initiated:
def get_original_items(items, with_str):
def _warn_source_paths(msg, items, *extra):
args = [len(items)]
args.extend(extra)
args.extend(x.source_path for x in items)
logger.warning('{}: {}'.format(msg, '\n%s' * len(items)), *args)
# warn if several items have the same lang
for lang, lang_items in groupby(items, attrgetter('lang')):
lang_items = list(lang_items)
if len(lang_items) > 1:
_warn_source_paths('There are %s items "%s" with lang %s',
lang_items, with_str, lang)
from: https://github/getpelican/pelican/blob/d5d792060cd5e4c3ff6da82359589b990fa83f27/pelican/utils.py.
Not working:
LOG_FILTER = [(logging.WARN, 'There are %s items "%s" with lang %s')]
avaris help
30 Sep 2022 trying approach from https://github/getpelican/pelican/discussions/3046
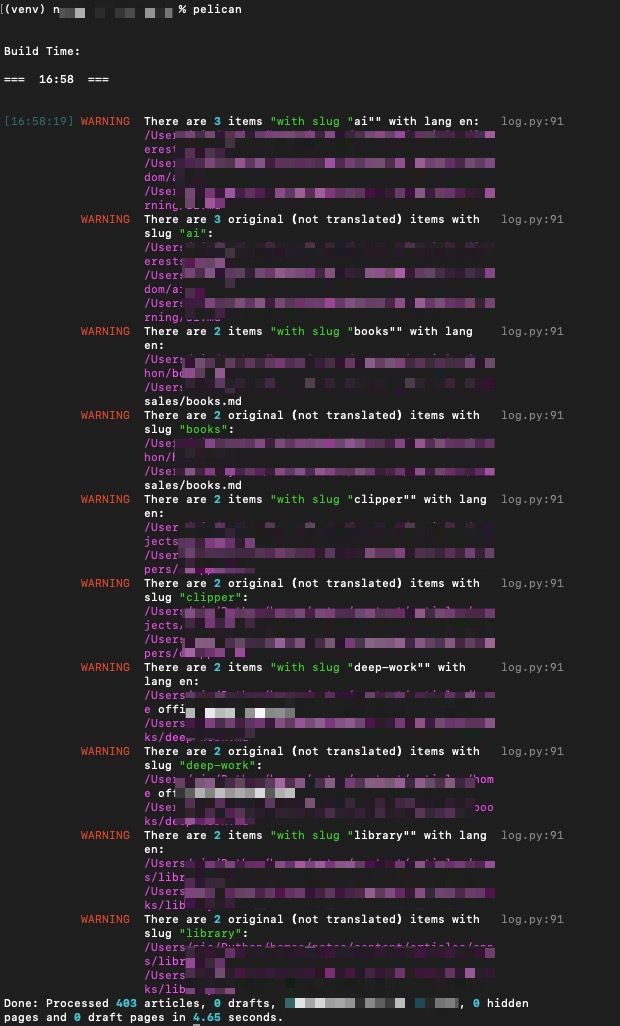
Baseline: 10 warnings as:
[08:44:52] WARNING There are 3 items "with slug "ai"" with lang en: log.py:91
/Users/xxx/content/articles/interests/ai.md
/Users/xxx/content/articles/learning/ai.md
/Users/xxx/content/articles/random/ai.md
WARNING There are 3 original (not translated) items with slug "ai": log.py:91
/Users/xxx/content/articles/interests/ai.md
/Users/xxx/content/articles/learning/ai.md
/Users/xxx/content/articles/random/ai.md
WARNING There are 2 items "with slug "books"" with lang en: log.py:91
/Users/xxx/content/articles/b2b sales/books.md
/Users/xxx/content/articles/python/books.md
WARNING There are 2 original (not translated) items with slug "books": log.py:91
/Users/xxx/content/articles/b2b sales/books.md
/Users/xxx/content/articles/python/books.md
WARNING There are 2 items "with slug "clipper"" with lang en: log.py:91
/Users/xxx/content/articles/helpers/clipper.md
/Users/xxx/content/articles/projects/clipper.md
WARNING There are 2 original (not translated) items with slug "clipper": log.py:91
/Users/xxx/content/articles/helpers/clipper.md
/Users/xxx/content/articles/projects/clipper.md
WARNING There are 2 items "with slug "deep-work"" with lang en: log.py:91
/Users/xxx/content/articles/books/deep-work.md
/Users/xxx/content/articles/home office/deep-work.md
WARNING There are 2 original (not translated) items with slug "deep-work": log.py:91
/Users/xxx/content/articles/books/deep-work.md
/Users/xxx/content/articles/home office/deep-work.md
WARNING There are 2 items "with slug "library"" with lang en: log.py:91
/Users/xxx/content/articles/apps/library.md
/Users/xxx/content/articles/books/library.md
WARNING There are 2 original (not translated) items with slug "library": log.py:91
/Users/xxx/content/articles/apps/library.md
/Users/xxx/content/articles/books/library.md
Suggested approach:
import logging
LOG_FILTER = [
(logging.WARN, 'There are %s items "%s" with lang %s: \n%s\n%s'), # 2 item warning
(logging.WARN, 'There are %s items "%s" with lang %s: \n%s\n%s\n%s'), # 3 item warning
(logging.WARN, 'There are %s items "%s" with lang %s: \n%s\n%s\n%s\n%s'), # 4 item warning
# ... so on. depending on your site and the kind of warnings you get
]
down to 5 warnings:
[08:51:40] WARNING There are 3 original (not translated) items with slug "ai": log.py:91
/Users/xxxx/content/articles/interests/ai.md
/Users/xxxx/content/articles/random/ai.md
/Users/xxxx/content/articles/learning/ai.md
WARNING There are 2 original (not translated) items with slug "books": log.py:91
/Users/xxxx/content/articles/python/books.md
/Users/xxxx/content/articles/b2b sales/books.md
WARNING There are 2 original (not translated) items with slug "clipper": log.py:91
/Users/xxxx/content/articles/projects/clipper.md
/Users/xxxx/content/articles/helpers/clipper.md
WARNING There are 2 original (not translated) items with slug "deep-work": log.py:91
/Users/xxxx/content/articles/books/deep-work.md
/Users/xxxx/content/articles/home office/deep-work.md
WARNING There are 2 original (not translated) items with slug "library": log.py:91
/Users/xxxx/content/articles/books/library.md
/Users/xxxx/content/articles/apps/library.md
tweaking with:
import logging
LOG_FILTER = [
(logging.WARN, 'There are %s items "%s" with lang %s: \n%s\n%s'), # 2 item warning
(logging.WARN, 'There are %s original (not translated) items with slug %s: \n%s\n%s'), # 2 item warning
(logging.WARN, 'There are %s items "%s" with lang %s: \n%s\n%s\n%s'), # 3 item warning
(logging.WARN, 'There are %s original (not translated) items with slug %s: \n%s\n%s\n%s'), # 3 item warning
(logging.WARN, 'There are %s items "%s" with lang %s: \n%s\n%s\n%s\n%s'), # 4 item warning
]
still 5 warnings 😕
tweaking again with:
import logging
LOG_FILTER = [
(logging.WARN, 'There are %s items "%s" with lang %s: \n%s\n%s'), # 2 item warning
(logging.WARN, 'There are %s original (not translated) items with slug "%s": \n%s\n%s'), # 2 item warning
(logging.WARN, 'There are %s items "%s" with lang %s: \n%s\n%s\n%s'), # 3 item warning
(logging.WARN, 'There are %s original (not translated) items with slug "%s": \n%s\n%s\n%s'), # 3 item warning
(logging.WARN, 'There are %s items "%s" with lang %s: \n%s\n%s\n%s\n%s'), # 4 item warning
]
still not working 🤔
keeping it running in the background, ongoing
best for development:
pelican -r (for reload) instead of just pelican
What tripped me up
paths
figuring out the path syntax to use for images (and pdfs, etc). From subfolder in content I now use:
<img class="header" src="{static}../../images/CP011_blog.svg" alt="CP011_blog.svg"/>
make vs pelican
using make html does not seem to take the OUTPUT_PATH = ' config in pelicanconf.py into consideration. Use the pelican command instead (no need to pass content source, settings file, or output dir each time, just running pelican in the project folder)
Need to explore further. For reference:
Makefile for a pelican Web site
Usage:
make html (re)generate the web site
make clean remove the generated files
make regenerate regenerate files upon modification
make publish generate using production settings
make serve [PORT=8000] serve site at http://localhost:8000
make serve-global [SERVER=0.0.0.0] serve (as root) to "0.0.0.0":80
make devserver [PORT=8000] serve and regenerate together
make devserver-global regenerate and serve on 0.0.0.0
make github upload the web site via gh-pages
Set the DEBUG variable to 1 to enable debugging, e.g. make DEBUG=1 html
Set the RELATIVE variable to 1 to enable relative urls
slug
the article slug can be defined in peliconconf.py to automatically use the Title: metadata (with FILENAME_METADATA = '(?P<title>.*)'), and can be overriden on an article basis by adding the Slug: metadata.
So:
Title: Hosting my static website with Github Pages
Tags:
will get the slug hosting-my-static-website-with-github-pages.html, whereas
Title: Hosting my static website with Github Pages
Tags:
Slug: github-pages
will get the slug github-pages.html
syntax highlighting
Pelican installs the syntax highlighter Pygments. Haven't read the Pygments doc though:

Changed the formatting of my code blocks to reflect my VS Code theme.
Tedious way:
- use same code in VS code and a rendered HTML version of it
- inspecting the rendered code provides the class used for it (eg
<span class="kn">from</span>= the initial "from" word in my script uses CSS class "kn") - classes can be found in
theme/static/css/pygment.css - using a colour picker (Aquarelo just installed from my SetApp subscription, I picked the color code for each highlight color in VS code, matched to its CSS class, and updated the
pygment.cssfile.
I'm sure there is an easier way.
Weirdly enough, some classes were missing in the pygments.css file. Added them manually to fix.
for code
3 ways:
1) my current default using ``` python:
print('this is how it will be displayed')
2) or starting each line with 4 spaces across code block, with the first line including language preceded by :::, eg ::: python. No need to close code block, indentation suffices.
print('this is how it will be displayed')
3) or starting each line with 4 spaces across code block, with shebang (indicates line numbers):
1 | |
(note to self: need to rework my css when line numbers are showing)
I have not been able to make 2) and 3) work.
Also not able to make the line highlights work with ``` python hl_lines="3 4" (from https://yakworks.github/docmark/extensions/codehilite/)
for tables:
Add to pelicanconf.py:
from markdown.extensions.tables import TableExtension
MARKDOWN = {
"extensions": [TableExtension()]
}
Note: adding the above broke my code syntax highlighting. Uncommenting it restored it.. and the table rendering still works. Not sure how/why.
26 Mar 2023 see details of extension at Python library: Python-Markdown
Markdown syntax:
header1 | header2 | header3 |
---|---|---|
A1 | A2 | A3 |
B1 | B2 | B3 |
C1 | C2 | C3 |
renders:
| header1 | header2 | header3 |
|---|---|---|
| A1 | A2 | A3 |
| B1 | B2 | B3 |
| C1 | C2 | C3 |
Can be styled with the thead/th and tbody/td CSS classes.
escaping quotes in article titles
See issue below when I tried to implement the pelican-search plugin, using Stork.
Stork was failing to read the .toml file (which contains all page links) because the title quotes were breaking the structure.
Learning: escape quotes in article titles, eg I \"like\" spam.
Variables
Not my case, but listing here if needed + logic can be re-used elsewhere I think:
To show "Authors" instead of "Author" when there are more than 1 authors for the same article:
<div>
{% set i = article.authors|count %}
{% if i != 1 %}
Authors:<br>
{% endif %}
{% if i == 1 %}
Author:<br>
{% endif %}
{% if article.authors %}
{% for author in article.authors %}
<a href="{{ SITEURL }}/{{ author.url }}">{{ author }}</a><br>
{% endfor %}
{% endif %}
</div>
source:

My Config file
28 Sep 2022 updated version:
AUTHOR = 'Nic'
SITENAME = "Nic's notes"
SITEURL = 'https://notes.nicolasdeville.com'
PATH = 'content'
OUTPUT_PATH = '/path/to/my/output/folder/'
DISPLAY_PAGES_ON_MENU = False
USE_FOLDER_AS_CATEGORY = True
DEFAULT_CATEGORY = 'misc'
ARTICLE_PATHS = ['articles',]
ARTICLE_URL = "{category}/{slug}"
ARTICLE_SAVE_AS = "{category}/{slug}/index.html"
PAGE_URL = "{slug}/"
PAGE_SAVE_AS = "{slug}/index.html"
CATEGORY_URL = "{slug}/"
CATEGORY_SAVE_AS = "{slug}/index.html"
CATEGORIES_URL = "categories/"
CATEGORIES_SAVE_AS = "categories/index.html"
FILENAME_METADATA = '(?P<slug>.*)' # makes Slug optional in markdown / uses filename instead
PAGE_PATHS = ['pages']
DEFAULT_DATE = 'fs'
DEFAULT_DATE_FORMAT = '%d %b %Y'
STATIC_PATHS = [
'images',
'extra',
'pdfs',
'pages',
'csvs',
]
EXTRA_PATH_METADATA = {
'extra/CNAME': {'path': 'CNAME'},
'extra/gitignore': {'path': '.gitignore'},
'extra/sitemap.xml': {'path': 'sitemap.xml'},
'extra/robots.txt': {'path': 'robots.txt'},
'extra/googlexxxxxxxxxx.html': {'path': 'googlexxxxxxxxxx.html'},
'extra/BingSiteAuth.xml': {'path': 'BingSiteAuth.xml'},
# added 220916
'extra/android-chrome-192x192.png': {'path': 'android-chrome-192x192.png'},
'extra/android-chrome-512x512.png': {'path': 'android-chrome-512x512.png'},
'extra/apple-touch-icon.png': {'path': 'apple-touch-icon.png'},
'extra/favicon-16x16.png': {'path': 'favicon-16x16.png'},
'extra/favicon-32x32.png': {'path': 'favicon-32x32.png'},
'extra/favicon.ico': {'path': 'favicon.ico'},
'extra/favicon.png': {'path': 'favicon.png'},
'extra/favicon.svg': {'path': 'favicon.svg'},
'extra/site.webmanifest': {'path': 'site.webmanifest'},
# added 220919
'extra/logo.png': {'path': 'logo.png'},
'extra/logo.svg': {'path': 'logo.svg'},
}
DEFAULT_LANG = 'en'
#With these settings, Pelican will create an archive of all your posts for the year
# at (for instance) posts/2011/index.html
# and an archive of all your posts for the month at posts/2011/Aug/index.html.
YEAR_ARCHIVE_SAVE_AS = '{date:%Y}/index.html'
MONTH_ARCHIVE_SAVE_AS = '{date:%Y}/{date:%m}/index.html'
AUTHOR_SAVE_AS = 'author/{slug}.html' # to avoid generating author page as it's only me.
# Feed generation is usually not desired when developing
FEED_ALL_ATOM = None
CATEGORY_FEED_ATOM = None
TRANSLATION_FEED_ATOM = None
AUTHOR_FEED_ATOM = None
AUTHOR_FEED_RSS = None
# Blogroll
LINKS = (
('Side project: indeXall.io', 'https://indeXall.io'),
('Services: BtoBSales.EU', 'https://btobsales.eu'),
)
# Social widget
SOCIAL = (
('Linkedin', 'https://www.linkedin.com/in/ndeville/'),
('Twitter', 'https://www.twitter.com/ndeville'),
)
DEFAULT_PAGINATION = 100
# THEME = '/Users/nic/Python/sandbox/home.nicolasdeville.com/pelican-themes/simple-bootstrap'
THEME = '/Users/nic/Python/homee/notes/theme'
OUTPUT_RETENTION = [".gitignore"] # probably of no use if not in `content` folder?
# to add capability to support tables. Source: https://www.dj-bauer.de/use-tables-in-pelican-markdown-en.html
# from markdown.extensions.tables import TableExtension
# MARKDOWN = {
# "extensions": [TableExtension()]
# }
SEARCH_HTML_SELECTOR = "main" # for the pelican plugin "search" using Stork. Using the default <main> tag means repeating sections can be carved out of search index.
### 220911 Adding Last Update timestamp on publish
from datetime import datetime
import pytz
# modify TIMEZONE to your timezone
TIMEZONE = 'Europe/Berlin'
# Publish Timestamp
build_timestamp = datetime.now(pytz.timezone(TIMEZONE))
BUILD_TIME = build_timestamp
# printing timestamp when publishing, to include in Git message and double-checking deployment
print(f"\n\nBuild Time:\n\n=== {build_timestamp.strftime('%H:%M')} ===\n\n")
# pelican-seo
# not working
SEO_REPORT = True
SEO_ENHANCER = True
SEO_ENHANCER_OPEN_GRAPH = True
SEO_ENHANCER_TWITTER_CARDS = True
LOGO = "https://ik.imagekit.io/vhucnsp9j1u/images/edelweiss_black_logo.svg"
# Table Of Contents
MARKDOWN = {
"extension_configs": {
# Needed for code syntax highlighting
"markdown.extensions.codehilite": {"css_class": "highlight"},
"markdown.extensions.extra": {},
"markdown.extensions.meta": {},
# This is for enabling the TOC generation
"markdown.extensions.toc": {"title": "Table of Contents"},
},
"output_format": "html5",
}
# 220923 suppressing warning messages for not translated messages
# not working
import logging
LOG_FILTER = [(logging.WARN, 'There are %s items "%s" with lang %s')]
# code blocks with line numbers
PYGMENTS_RST_OPTIONS = {
'linenos': 'table'
}
# Uncomment following line if you want document-relative URLs when developing
# RELATIVE_URLS = True
Hosting
Once generated, I'm using Github Pages to host for free.
Hosting my static website(s) with Github Pages
publish
in Terminal:
cdto output directorygit add .(adding all files from folder)git commit -m 'daily update'(committing with message)git push origin main(push all static files to Github - publishing is automated by Github)
Search
Stork

especially:
on Github:

Javascript API Reference:
creator's personal website, with nice search input animation:

Plus plug-in:
16 Jul 2022 Testing notes:
- install Stork first
brew install stork-search/stork-tap/stork
- then install Pelican plugin
pip3 install pelican-search
- implement CSS & HTML changes. Test using
<body>instead of adding<main>everywhere. - generate index file: manually each time or does the plugin take care of that? TO TEST
Questions:
- SEARCH_HTML_SELECTOR = "main": why not use simply <body>?
-> Answer: with repeating content in header and footer, using <body> results in showing all pages in search results when using a search variable included in those.
First implementation - error:
% pelican
[20:39:09] CRITICAL Exception: Search plugin reported Error: __init__.py:566
Couldn't read the configuration file: Cannot
parse config as TOML. Stork recieved error:
`expected newline, found an identifier at
line 278 column 13`
Solved: https://github/pelican-plugins/search/issues/3
The issue was that some of my article titles had quotes that were not escaped.
26 Jul 2022 noticed an error when searching on a page other than the homepage (wrong path). TODO investigate.
=> solved with latest update.
25 Sep 2022 many notes now, making search a bit more difficult.
Checked if filtering by category helps - does not.
Workaround: add search code: XXX to pages were quick access is required, where XXX is a unique combination of characters in the Stork index.
Algolia Search: A Plugin for Pelican
decided against, preferring Stork (see above)
Add Build Timestamp ("Last Updated") to Pelican Site Automatically
12 Sep 2022 implemented.
SEO
16 Sep 2022 testing:
increased build time to 5.72-10.49 seconds from 3+ seconds!
added to pelicancond.py:
# pelican-seo
SEO_REPORT = True
SEO_ENHANCER = True
SEO_ENHANCER_OPEN_GRAPH = True
SEO_ENHANCER_TWITTER_CARDS = True
LOGO = "https://ik.imagekit.io/vhucnsp9j1u/images/edelweiss_black_logo.svg"
Did not manage to make it work - only the SEO Analysis worked but not SEO Enhancer.
Uninstalled.
Will implement SEO best practices manually - more in the SEO section of Building this site: notes.nicolasdeville.com
Plugins to test
more Categories
for subcategories and more than 1 category per article
sitemap
for auto-generation of sitemap.xml
Staticman | comments for static sites
found here:

Github:
theme example + word count + search feature
summary plugin
image-process
additional resources
markdown syntax
helpful guide at the beginning to get used to the Markdown syntax

Code HiLite
Pelican Folder Structure
helped me rework my project structure based on subfolfers in content

Pelican's USE_FOLDER_AS_CATEGORY setting and behaviour
clear once logic is understood, but good overview:
