18 Sep 2022
| Library resources | |
|---|---|
| PyPI | https://pypi.org/project/SpeechRecognition/ |
| Github | https://github.com/Uberi/speech_recognition |
| Documentation | --- |
pip3 install SpeechRecognition
Example
#!/usr/bin/env python3
import speech_recognition as sr
# obtain path to "english.wav" in the same folder as this script
from os import path
AUDIO_FILE = path.join(path.dirname(path.realpath(__file__)), "english.wav")
# AUDIO_FILE = path.join(path.dirname(path.realpath(__file__)), "french.aiff")
# AUDIO_FILE = path.join(path.dirname(path.realpath(__file__)), "chinese.flac")
# use the audio file as the audio source
r = sr.Recognizer()
with sr.AudioFile(AUDIO_FILE) as source:
audio = r.record(source) # read the entire audio file
# recognize speech using Sphinx
try:
print("Sphinx thinks you said " + r.recognize_sphinx(audio))
except sr.UnknownValueError:
print("Sphinx could not understand audio")
except sr.RequestError as e:
print("Sphinx error; {0}".format(e))
# recognize speech using Google Speech Recognition
try:
# for testing purposes, we're just using the default API key
# to use another API key, use `r.recognize_google(audio, key="GOOGLE_SPEECH_RECOGNITION_API_KEY")`
# instead of `r.recognize_google(audio)`
print("Google Speech Recognition thinks you said " + r.recognize_google(audio))
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
# recognize speech using Google Cloud Speech
GOOGLE_CLOUD_SPEECH_CREDENTIALS = r"""INSERT THE CONTENTS OF THE GOOGLE CLOUD SPEECH JSON CREDENTIALS FILE HERE"""
try:
print("Google Cloud Speech thinks you said " + r.recognize_google_cloud(audio, credentials_json=GOOGLE_CLOUD_SPEECH_CREDENTIALS))
except sr.UnknownValueError:
print("Google Cloud Speech could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Cloud Speech service; {0}".format(e))
# recognize speech using Wit.ai
WIT_AI_KEY = "INSERT WIT.AI API KEY HERE" # Wit.ai keys are 32-character uppercase alphanumeric strings
try:
print("Wit.ai thinks you said " + r.recognize_wit(audio, key=WIT_AI_KEY))
except sr.UnknownValueError:
print("Wit.ai could not understand audio")
except sr.RequestError as e:
print("Could not request results from Wit.ai service; {0}".format(e))
# recognize speech using Microsoft Azure Speech
AZURE_SPEECH_KEY = "INSERT AZURE SPEECH API KEY HERE" # Microsoft Speech API keys 32-character lowercase hexadecimal strings
try:
print("Microsoft Azure Speech thinks you said " + r.recognize_azure(audio, key=AZURE_SPEECH_KEY))
except sr.UnknownValueError:
print("Microsoft Azure Speech could not understand audio")
except sr.RequestError as e:
print("Could not request results from Microsoft Azure Speech service; {0}".format(e))
# recognize speech using Microsoft Bing Voice Recognition
BING_KEY = "INSERT BING API KEY HERE" # Microsoft Bing Voice Recognition API keys 32-character lowercase hexadecimal strings
try:
print("Microsoft Bing Voice Recognition thinks you said " + r.recognize_bing(audio, key=BING_KEY))
except sr.UnknownValueError:
print("Microsoft Bing Voice Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Microsoft Bing Voice Recognition service; {0}".format(e))
# recognize speech using Houndify
HOUNDIFY_CLIENT_ID = "INSERT HOUNDIFY CLIENT ID HERE" # Houndify client IDs are Base64-encoded strings
HOUNDIFY_CLIENT_KEY = "INSERT HOUNDIFY CLIENT KEY HERE" # Houndify client keys are Base64-encoded strings
try:
print("Houndify thinks you said " + r.recognize_houndify(audio, client_id=HOUNDIFY_CLIENT_ID, client_key=HOUNDIFY_CLIENT_KEY))
except sr.UnknownValueError:
print("Houndify could not understand audio")
except sr.RequestError as e:
print("Could not request results from Houndify service; {0}".format(e))
# recognize speech using IBM Speech to Text
IBM_USERNAME = "INSERT IBM SPEECH TO TEXT USERNAME HERE" # IBM Speech to Text usernames are strings of the form XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
IBM_PASSWORD = "INSERT IBM SPEECH TO TEXT PASSWORD HERE" # IBM Speech to Text passwords are mixed-case alphanumeric strings
try:
print("IBM Speech to Text thinks you said " + r.recognize_ibm(audio, username=IBM_USERNAME, password=IBM_PASSWORD))
except sr.UnknownValueError:
print("IBM Speech to Text could not understand audio")
except sr.RequestError as e:
print("Could not request results from IBM Speech to Text service; {0}".format(e))
from https://github.com/Uberi/speech_recognition/blob/master/examples/audio_transcribe.py
Speech recognition services
Google Speech Recognition
Google Cloud Speech
Wit.ai

Facebook (Meta) product - staying away.
Microsoft Azure Speech
Microsoft Bing Voice Recognition
Houndify

SoundHound | Technology for a voice-enabled world
The Houndify Voice AI platform
Try free, but can't find pricing.
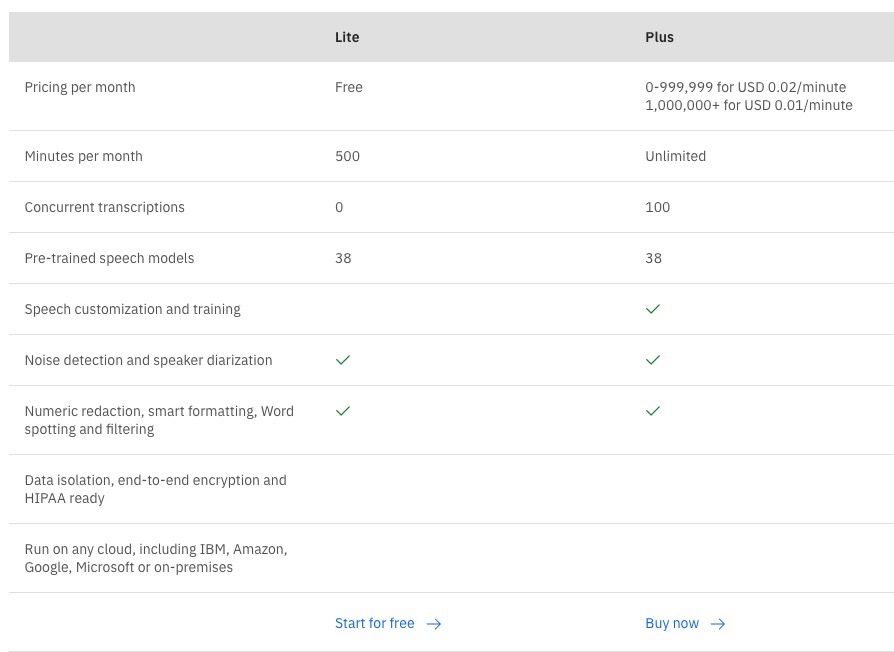
IBM Speech to Text

Pricing: