
2020 started using.

External storage
Supports the following type of origin:
- Amazon S3 bucket origin
- S3-Compatible storages
- Wasabi Storage
- Ali Storage
- Digital Ocean Spaces
- Any web server origin
- Web proxy
- Azure Blob storage
- Google Storage
- Firebase Storage
- Cloudinary backup bucket
Current usage
23 Mar 2023
My account has been dormant/passive, just using the free tier, for the country flags images on my various projects.

26 Mar 2023
Aiming to move hosting for this site from Github Pages !helpers/github-pages to Netlify !helpers/netlify & ImageKit - mainly for deployment speed optimisation but also load times (Github Pages works well but Netlify seems more optimised).
See API use below.
Image transformations
image resizing
width 200px: add /tr:w-200/ before file, eg. https://ik.imagekit.io/demo/tr:w-200/medium_cafe_B1iTdD0C.jpg
width 40%: add /tr:w-0.4/ before file, eg. https://ik.imagekit.io/demo/tr:w-0.4/medium_cafe_B1iTdD0C.jpg
height: tr:h-200
width 400px and aspect ratio 4:3: /tr:ar-4-3,w-400/
API
Python SDK:

working script
Working script to upload my images folder for my Notes site to ImageKit.
Both for initial upload & ongoing, ie included in shell script when updating site.
import base64
from imagekitio import ImageKit
from imagekitio.models.UploadFileRequestOptions import UploadFileRequestOptions
imagekit = ImageKit(
private_key=IMAGEKIT_PRIVATE_KEY,
public_key=IMAGEKIT_PUBLIC_KEY,
url_endpoint=IMAGEKIT_URL_ENDPOINT
)
def encode_image_base64(image_path):
with open(image_path, 'rb') as image_file:
encoded_string = base64.b64encode(image_file.read())
return encoded_string.decode('utf-8')
## Not needed for now / keeping for reference
# def read_image_binary(image_path):
# with open(image_path, 'rb') as image_file:
# binary_data = image_file.read()
# return binary_data
def add_image_to_imagekit(image_path, file_name, folder):
base64_encoded_image = encode_image_base64(image_path)
## Not needed for now / keeping for reference
# extensions = [
# {
# 'name': 'remove-bg',
# 'options': {
# 'add_shadow': True,
# 'bg_color': 'pink'
# }
# },
# {
# 'name': 'google-auto-tagging',
# 'minConfidence': 80,
# 'maxTags': 10
# }
# ]
options = UploadFileRequestOptions( # see https://docs.imagekit.io/api-reference/upload-file-api/client-side-file-upload#request-structure-multipart-form-data
use_unique_file_name=False, # false = uploaded with provided filename / any existing file with the same name is replaced.
# tags=['abc', 'def'],
folder=folder, # passing hierarchy of folders is allowed, eg. 'folder1/folder2/folder3'
is_private_file=False,
# custom_coordinates='10,10,20,20',
# response_fields=['tags', 'custom_coordinates', 'is_private_file', 'embedded_metadata', 'custom_metadata'],
# extensions=extensions,
# webhook_url='https://webhook.site/xxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx',
overwrite_file=True,
# overwrite_ai_tags=False,
# overwrite_tags=False,
# overwrite_custom_metadata=True,
# custom_metadata={'test_metadata': 12},
)
result = imagekit.upload_file(
file=base64_encoded_image, # required
file_name=file_name, # required
options=options
)
print(f"\n{result.response_metadata.raw=}")
return result
image_path = '/path/to/file/230315-failed-pings.jpg'
file_name = os.path.basename(image_path)
print(f"{file_name=}")
folder = image_path.replace('/path/to/root/image/folder/', '').replace(file_name, '')
print(f"{folder=}")
add_image_to_imagekit(image_path, file_name, folder)
to manage secrets in environment variables (eg private_key=IMAGEKIT_PRIVATE_KEY) see !python/library-dotenv
Library upload
26 Mar 2023
upstream connect error or disconnect/reset before headers. reset reason: connection termination after 1,253 uploads 😢
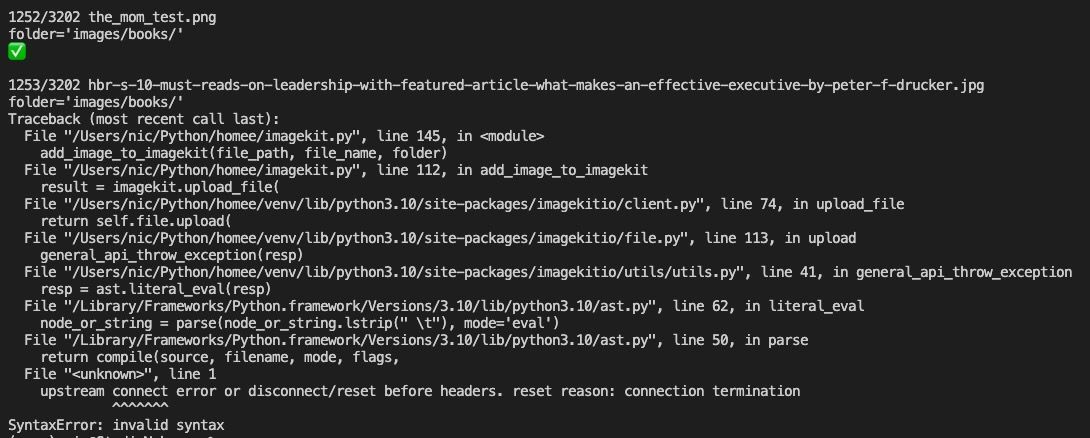
Need to fetch first what has been uploaded before retrying.
def get_existing_files(v=False):
def fetch_files_batch(skip, limit=1000):
options = ListAndSearchFileRequestOptions(
limit=limit,
skip=skip,
)
result = imagekit.list_files(options=options)
return result.response_metadata.raw
def get_all_file_paths():
all_file_paths = []
batch_size = 1000
skip = 0
while True:
batch = fetch_files_batch(skip, batch_size)
if not batch: # No more files to fetch
break
for r in batch:
file_path = r['filePath']
if v:
print(file_path)
all_file_paths.append(file_path)
skip += batch_size
return all_file_paths
all_paths = get_all_file_paths()
all_images_paths = [x for x in all_paths if x.startswith('/images/')]
print(f"\nℹ️ {len(all_images_paths)} files found in Imagekit")
return all_images_paths
so..
# Get all files in local directory
all_file_paths = my_utils.fetch_file_paths_from_all_dirs('/local/path/to/images')
count_total = len(all_file_paths)
print(f"\nℹ️ {count_total} files found in local directory")
# Get all files in Imagekit
existing_files = get_existing_files()
print(f"\n{len(existing_files)} files found in Imagekit")
# Get all files in local directory that are not in Imagekit
remaining_file_paths = [x for x in all_file_paths if x.replace("/Users/xxxx/path/to/content", "", 1) not in existing_files]
count_todo = len(remaining_file_paths)
print(f"\n{count_todo} files remaining")
for file_path in remaining_file_paths:
Supports PDFs, MP4s, and other non-image files
List of supported non-image file extensions
.js
.css
.svg
.json
.pdf
.mp4
.txt
.html
See full list & non-supported file extensions: https://docs.imagekit.io/features/non-image-file-compression#non-image-file-extensions
01 Jan 2024
Upload script failed with 80Mb PDF.
Seems 26Mb is the limit on the free plan, though not clearly stated.
Worked fine with 25Mb PDF.