
06 Sep 2022 UPDATE
Well, it appears there is a much easier solution 😅
-
Plug your Kindle into your computer.
-
Navigate through the files on the Kindle and look for the file called
My Clippings.txt
.. and that's it. All the highlights are in this (heavy) text file!
At least it was a fun challenge and learning experience below! 😁
07 Sep 2022
Limitation is that the My Clippings.txt obviously only retains highlights made locally on that particular Kindle device.
So the below method from July is still relevant if highlights were made on an old Kindle, or from different Kindle devices (or apps).
The .txt file looks like that:
==========
Tech-Powered Sales (Michael, Justin)
- Your Highlight on page 239 | location 4471-4492 | Added on Sunday, 19 December 2021 13:24:06
==========
Tech-Powered Sales (Michael, Justin)
- Your Highlight on page 240 | location 4492-4496 | Added on Sunday, 19 December 2021 13:24:22
==========
MEDDICC: Using the Powerful MEDDIC, MEDDICC, and MEDDPICC Enterprise Sales Framework to Close High-Value Deals and Maximize Business Growth (Whyte, Andy)
- Your Highlight on page 11 | location 61-63 | Added on Sunday, 19 December 2021 13:31:38
During this class, we conducted an exercise (that I still do today with various sales teams) called: Why Do We Win? Why Do We Lose? Why Do Deals Slip?
==========
MEDDICC: Using the Powerful MEDDIC, MEDDICC, and MEDDPICC Enterprise Sales Framework to Close High-Value Deals and Maximize Business Growth (Whyte, Andy)
- Your Highlight on page 25 | location 257-260 | Added on Friday, 24 December 2021 11:09:58
Here is the script to generate Markdown from the .txt file.
The "tricky" bit was to figure out the logic to put data together across a varying number of text rows.
The loop_counter implemented below solved this.
# default boilerplate here. See python/boilerplate.
####################
# 220907 Generate highlights markdown from Kindle's My Clippings.txt
test = False
from collections import defaultdict
select_title = 'Learn JavaScript Quickly'
count_highlight = 0
loop_counter = 0
loop_index = -1
highlights = []
with open("kindle/My Clippings.txt", 'r') as df:
lines = df.readlines()
for line in lines:
count += 1
line = line[:-1] # remove EOL \n
if '\ufeff' in line:
line = line.replace('\ufeff', '')
### Check
# if line not in skip:
# if count < 100:
# print(count, repr(line))
### Highlight loop
if count > 4: # skip first lines
loop_counter += 1
if "====" in line:
count_highlight += 1
loop_counter = 1 # reset loop counter for each highlight block to identify rows
loop_index += 1 # new loop index for each highlight block
if loop_counter == 2:
title = line.replace('\n', '')
if test:
print(count, loop_index, repr(title))
highlights.append([title])
if loop_counter == 3:
location = line.replace('\n', '')
location = location.replace('- Your Highlight on ', '')
location = location.replace('- Your Highlight at ', '')
location = location.replace('- Your Note on ', '')
parts = location.split(' | ')
location = parts[0]
if test:
print(count, loop_index, repr(location))
highlights.insert(loop_index, highlights[-1:][0].append(location))
if loop_counter == 5:
highlight = line.replace('\n', '')
if test:
print(count, loop_index, repr(highlight))
highlights.insert(loop_index, highlights[-1:][0].append(highlight))
highlights = [x for x in highlights if x is not None]
print()
if test:
pp.pprint(highlights)
### Convert highlights to list of tuples
highlights = [tuple(x) for x in highlights]
# for x in highlights:
# print(type(x))
if test:
print(f"\nhighlights:\n")
for index, value in enumerate(highlights):
print(index, value)
highlights_dict = defaultdict(list)
if test:
print(f"\n\nBuilding highlights dict:\n")
for title, location, highlight in highlights:
if test:
if select_title in title:
print(f"building highlights_dict with: {title=}", f"{location=}", f"{highlight=}")
highlights_dict[title].append((location, highlight))
# highlights_dict = dict of list with tuples
print(f"\n\nALL BOOK TITLES WITH HIGHLIGHTS:\n")
for index, book_title in enumerate(highlights_dict):
print(index + 1, book_title)
count_max_print = 0
max_print = 100
for title,list_highlights in highlights_dict.items():
if select_title in title:
print(f"\n\nBOOK: {title}\n")
for highlight in list_highlights:
# count_max_print += 1
# if count_max_print > max_print:
# Inserting values in my custom HTML block for book quotes
html = f"<div class=\"book_quote\">\n<div class=\"book_quote_highlight\">{highlight[1]}</div>\n<div class=\"book_quote_location\">{highlight[0]}</div></div>\n"
print(html)
########################################################################################################
# default boilerplate here. See python/boilerplate.
15 Jul 2022
I'm trying to consolidate a list of all the books I have read. This includes my Kindle library, which has been the primary consumption method over the last 10 years.
It does not seem that there is an easy way to get one's Kindle data from Amazon (is that not a breach of some kind? At the very least it's bad software practice these days).
So I went ahead with the only way I know: scraping data with Python.
Ideally, one would query the pages directly on the server (calls with requests library) but as they sit behind a login, it was too tiresome to figure out the authentication (always a pain).
So:
- Login to your Amazon account, and go to
Manage Your Content and Devices- resulting in this URL for me, not sure if universal/consistent:

- Save each page listing your books in a folder, as
Webpage, Complete(thoughWebpage, HTML Onlyshould do the trick too).
Analysing the HTML code of one, we can identify the needed tags we need to target:
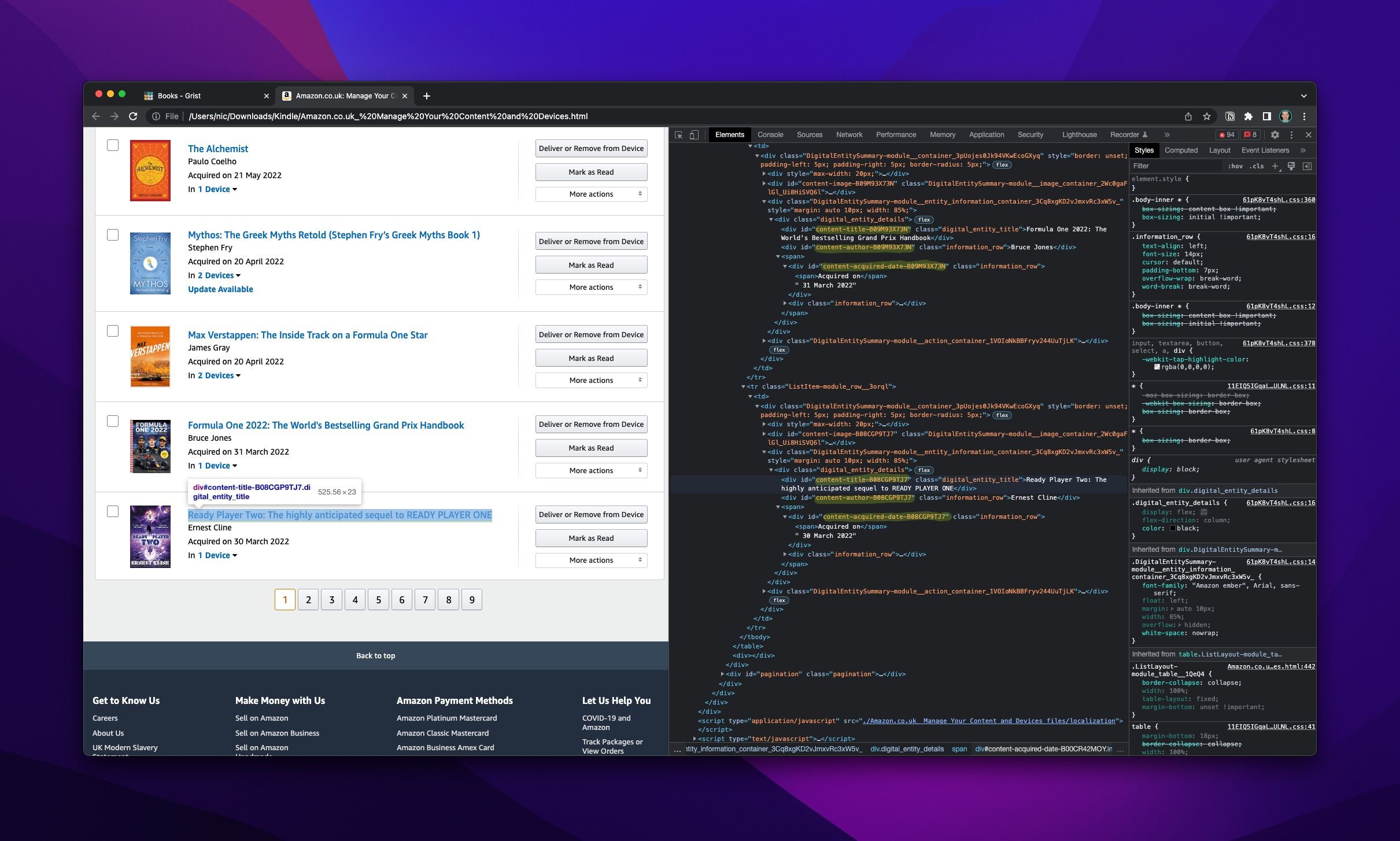
- This is the basic script used to scrape the relevant data from each page:
from bs4 import BeautifulSoup
import re
from slugify import slugify # to slugify book titles (also used as ID for gross deduplication)
file = '/path/to/folder/Kindle/Amazon.co.uk_ Manage Your Content and Devices.html'
soup = BeautifulSoup(open(file), 'html.parser')
books = soup.find_all(class_='ListItem-module_row__3orql')
for x in books:
# this piece is what took me the most time to figure out, helping target CSS IDs STARTING WITH a specific string as each has a custom ID appended with a random string: {"id" : lambda L: L and L.startswith('content-title')})
title_block = x.find("div", {"id" : lambda L: L and L.startswith('content-title')}).text
if ':' in title_block: # to separate title and tagline, where tagline is in the title, eg 'title: tagline'
title = title_block.split(':')[0]
tagline = title_block.split(':')[1]
else:
title = title_block
tagline = ''
slug = slugify(title) # slugify the title. Used for deduplication, cover image naming, file naming and slug definition
print(f"{title=}")
print(f"{slug=}")
print(f"{tagline=}")
# same lambda logic to target the other tag based on CSS id starting with
author = x.find("div", {"id" : lambda L: L and L.startswith('content-author')}).text
print(f"{author=}")
date = x.find("div", {"id" : lambda L: L and L.startswith('content-acquired-date')}).text
print(f"{date=}")
print()
To run the script on all files in the folder where the HTML files have been downloaded, I just add:
import os
for root, dirs, files in os.walk("/path/to/folder/with/HTML/files"):
for name in files:
if name.endswith((".html")):
Instead of just printing, you can export the data to the target of your choice.
Grist in my case:

with this addition to the code:
if slug not in books_slugs:
count_added += 1
print(f"{count_added} ADDED in Grist: {title}")
grist_PE.Books.add_records('Master', [
{ 'Title': title,
'Author': author,
'Slug': slug,
'Tagline': tagline,
'Bought': date,
'Cover': f"book_{slug}.jpg",
}
])