
Branched out from Scraping APIs
Table of Contents

14 Apr 2023
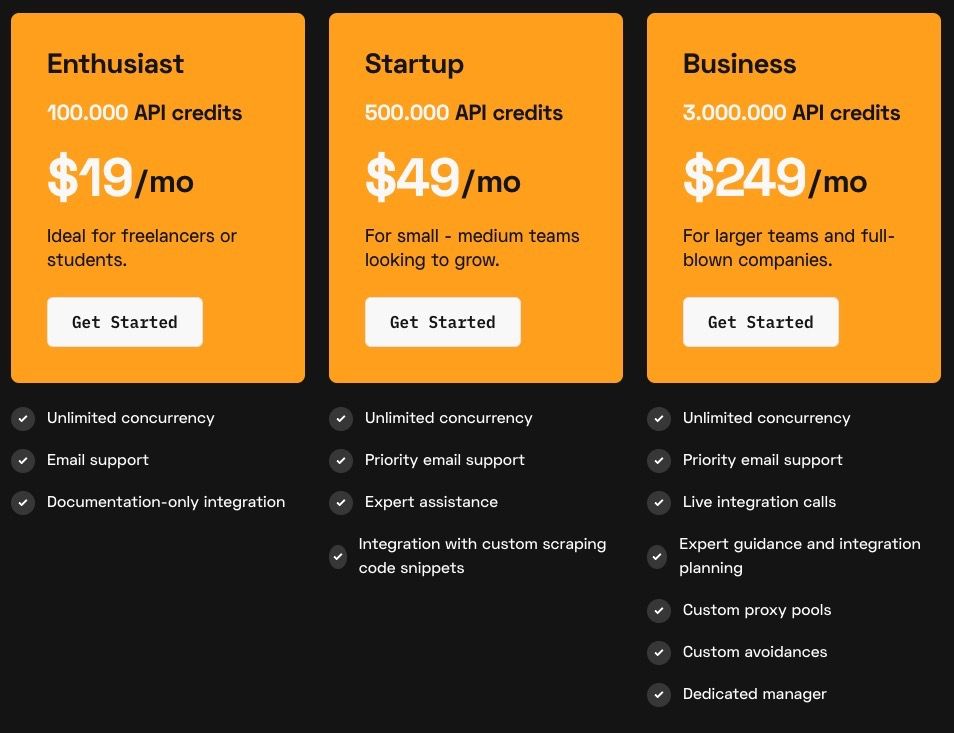
Starting to test on free plan.
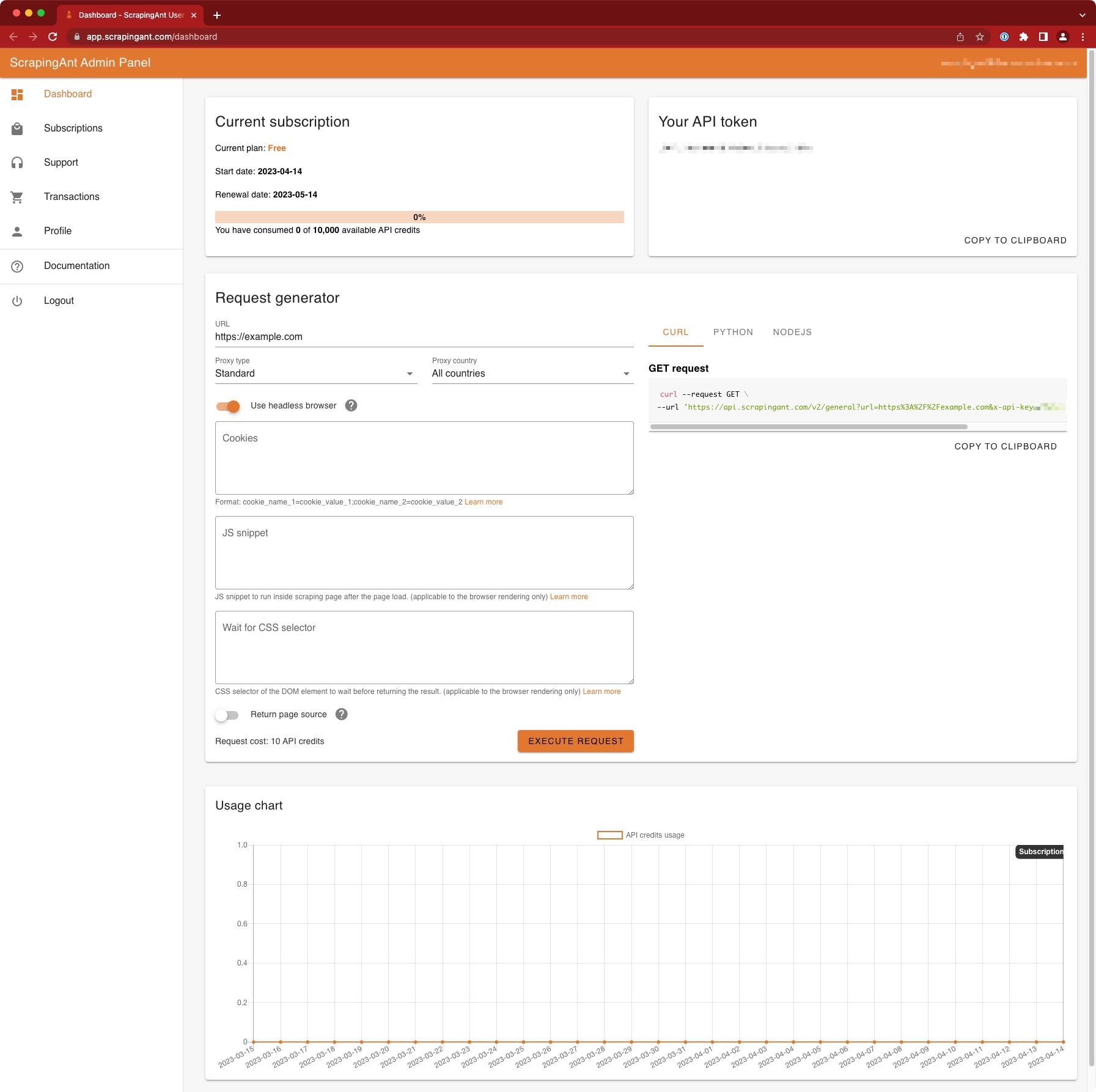
Basic Use
import requests
url = 'https://api.scrapingant.com/v2/general'
params = {
'url': 'https://example.com',
'x-api-key': '<YOUR-API-KEY>'
}
response = requests.get(url, params=params)
print(response.text)
working function
def get_soup(url):
request_url = 'https://api.scrapingant.com/v2/general'
params = {
'url': url,
'x-api-key': SCRAPINGANT_API_KEY,
'browser': True, # default: True / Set to True for JS rendering (10 credits), False otherwise (1 credit)
'proxy_country': 'GB', # default: world
'return_page_source': False, # default: False
}
response = requests.get(request_url, params=params)
html_text = response.text
soup = BeautifulSoup(html_text, 'html.parser')
return soup
using class selector
When website uses JS to load content, you can use the class selector option to ensure data is only returned once that CSS class is availabe.
CSS class (as .hero-unit) needs to be URL encoded.
request_url = 'https://api.scrapingant.com/v2/general'
params = {
'url': url,
'x-api-key': SCRAPINGANT_API_KEY,
'browser': True, # Set to True for JS rendering (10 credits), False otherwise (1 credit)
'proxy_country': 'GB',
'wait_for_selector': urllib.parse.quote('.hero-unit'),
}
response = requests.get(request_url, params=params)
See
Wait for CSS selector | ScrapingAnt | Web Scraping API
scrapingant.com
API client
Python API client | ScrapingAnt | Web Scraping API
scrapingant.com
| Library resources | |
|---|---|
| PyPI | --- |
| Github | https://github.com/ScrapingAnt/scrapingant-client-python |
| Documentation | https://docs.scrapingant.com/python-client |
Getting Started
pip install scrapingant-client
Usage
from scrapingant_client import ScrapingAntClient
client = ScrapingAntClient(token='<YOUR-SCRAPINGANT-API-TOKEN>')
# Scrape the example.com site.
result = client.general_request('https://example.com')
html = result.content
print(html)
Error codes
| HTTP status code | Reason |
|---|---|
| 400 | Wrong request format. Make sure that you're using a proper JSON input. |
| 403 | The API token is wrong or you have exceeded the API credits limit. |
| 404 | The requested URL is not reachable. Please, check it in your browser or try again. |
| 405 | The API endpoint can only be accessed using the following HTTP methods: GET, POST, PUT, DELETE. |
| 409 | Concurrent requests limit exceeded. Please, try again or upgrade to the paid plan |
| 422 | Invalid value provided. Please, look into detail for more info. |
| 423 | The anti-bot detection system has detected the request. Please, retry or change the request settings. |
| 500 | Something went wrong with the server side code. Rare case. We're recommending to contact us in this case. |
Response example
apparent_encoding: utf-8
close: <bound method Response.close of <Response [404]>>
connection: <requests.adapters.HTTPAdapter object at 0x1069c6860>
content: b'{"detail":"This site can\xe2\x80\x99t be reached"}'
cookies: <RequestsCookieJar[]>
elapsed: 0:01:00.988698
encoding: utf-8
headers: {'Content-Length': '41', 'Content-Type': 'application/json', 'Date': 'Sat, 15 Apr 2023 11:11:07 GMT', 'Server': 'uvicorn', 'Vary': 'Accept-Encoding'}
history: []
is_permanent_redirect: False
is_redirect: False
iter_content: <bound method Response.iter_content of <Response [404]>>
iter_lines: <bound method Response.iter_lines of <Response [404]>>
json: <bound method Response.json of <Response [404]>>
links: {}
next: None
ok: False
raise_for_status: <bound method Response.raise_for_status of <Response [404]>>
raw: <urllib3.response.HTTPResponse object at 0x106c63040>
reason: Not Found
request: <PreparedRequest [GET]>
status_code: 404
text: {"detail":"This site can’t be reached"}
url: https://api.scrapingant.com/v2/general?url=https%3A%2F%2Fbit.ly%2F3K8jfVx&x-api-key=c967d3da0a484315a5ecbb2aaaeb367a&browser=False&proxy_country=GB&return_page_source=True
AI extraction
27 Sep 2023
Launched AI data extraction.
Can handle requests like extracting product title, price(number), full description, reviews(list: review title, review content).
Instructions: https://docs.scrapingant.com/ai-data-extraction/ai-extractor
Price seems prohibitive though:
each 30 characters of input and output text cost 1 API credit
https://docs.scrapingant.com/credits-cost#ai-extractor-cost
So a webpage with 30k characters would cost 1k credits!